Model Development and Optimization: Fine-Tuning, Pruning, and Efficiency
MLOps Part 9: A deep dive into model fine-tuning and compression, specifically pruning and related improvements.
Recap
Before we dive into Part 9 of this MLOps and LLMOps crash course, let’s quickly recap what we covered in the previous part.
In Part 8, we discussed some key points regarding the fundamentals of the modeling stage of the machine learning system lifecycle.
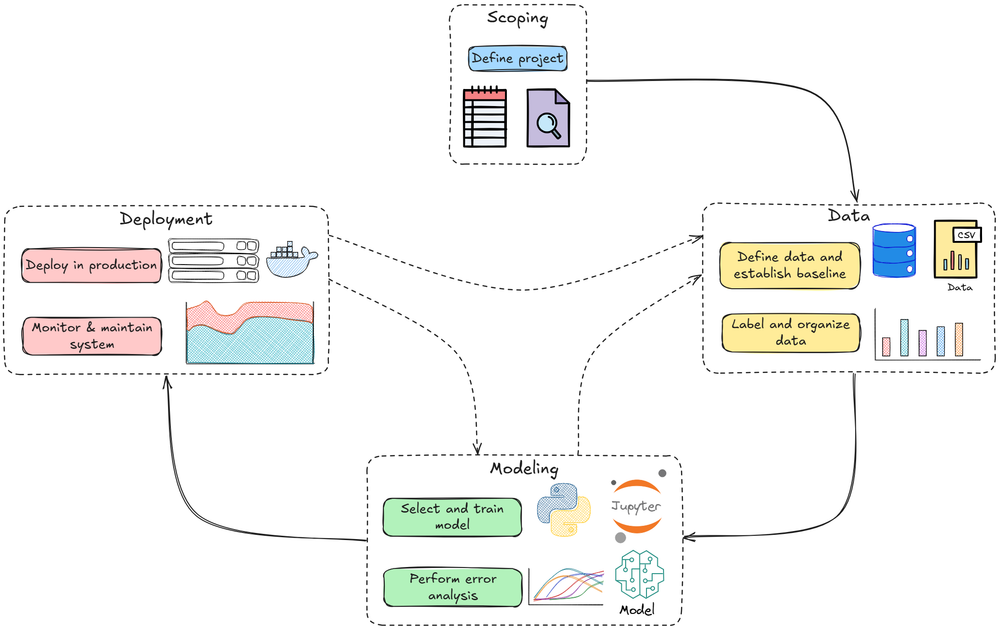
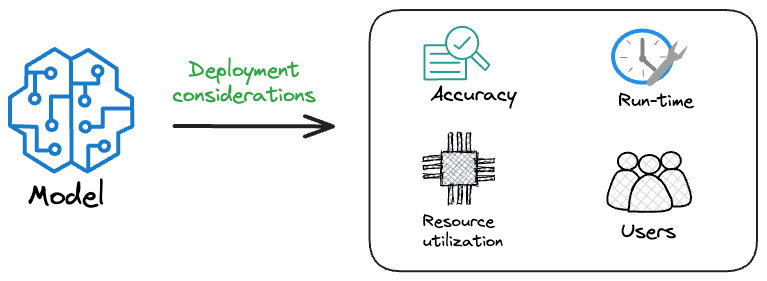
We started by understanding the requirements of an ML model in production settings and explored key points and tips to keep in mind for model selection and development.
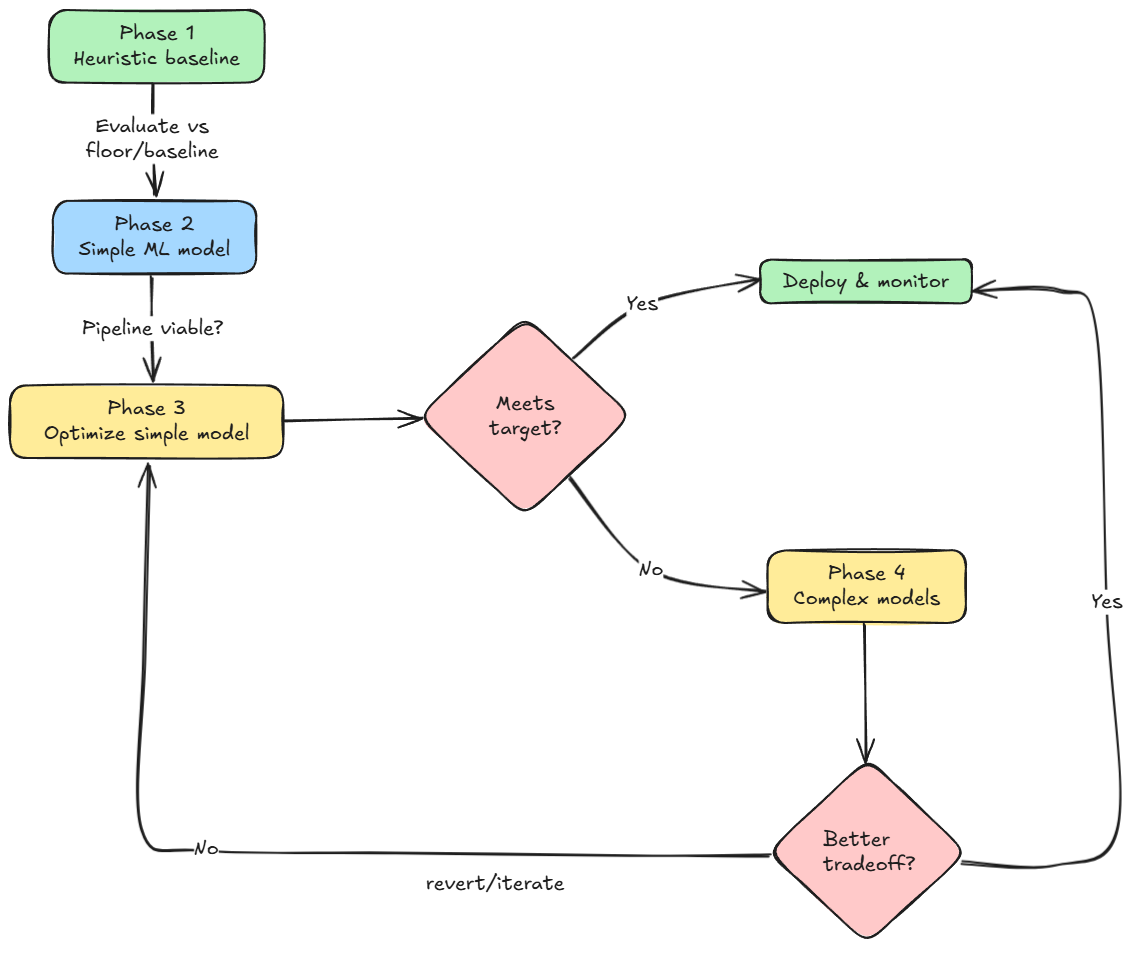
Next, we saw the four phases of ML model development and deployment, which gave us the framework to approach any task/problem in a systematic manner.
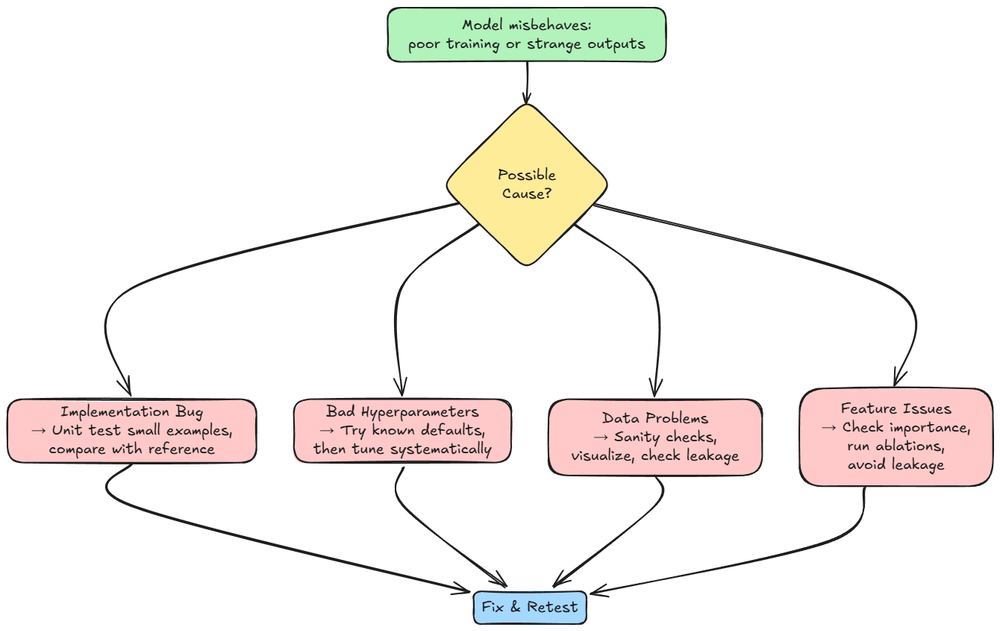
From there we dived into the issues related to model training, and debugging principles for the same.
Finally, we explored one aspect of model optimization by understanding HPO (hyperparameter optimization) with detailed concepts and a hands-on demo.
If you haven’t explored Part 8 yet, we strongly recommend going through it first since it lays the conceptual scaffolding that’ll help you better understand what we’re about to dive into here.
Read it here:

In this chapter, we’ll continue ahead with the modeling phase itself, understanding fine-tuning and diving deep into concepts like model compression.
As always, every idea and notion will be backed by concrete examples, walkthroughs, and practical tips to help you master both the idea and the implementation.
Let’s begin!
Model optimization
A powerful optimization technique is to leverage pre-trained models and fine-tune them on your task.
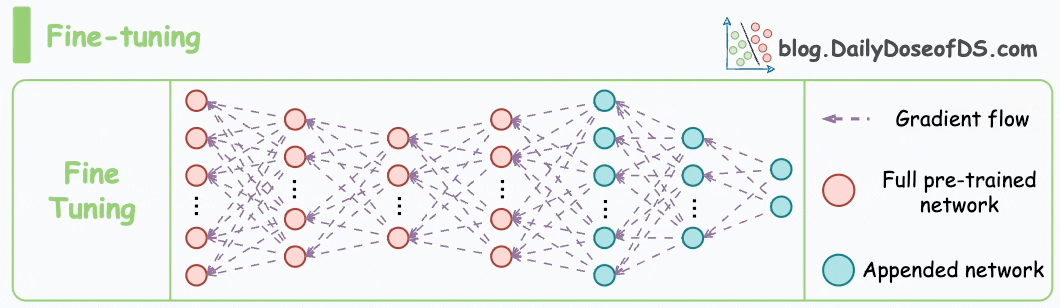
Fine-tuning is a subtype of transfer learning and is especially prevalent in deep learning for computer vision and natural language processing:
- In vision, models like ResNet or EfficientNet pre-trained on ImageNet have learned rich feature representations. Instead of training a CNN from scratch on your image dataset, you can take a pre-trained network and fine-tune it (or even just use it as a fixed feature extractor). This often yields better performance with much less data and compute.
- In NLP, large language models (BERT, GPT, etc.) are pre-trained on vast corpora. Fine-tuning them on a specific text classification or QA task has become the standard because it dramatically boosts performance compared to training from zero.
Why fine-tuning works?
Pre-trained models have learned general patterns (edges and textures in images; syntax and semantic structures in language) that are relevant to many tasks.
Fine-tuning adapts these general features to the specifics of your task. It’s like starting a new problem with a head start, because a lot of low-level learning is already done.
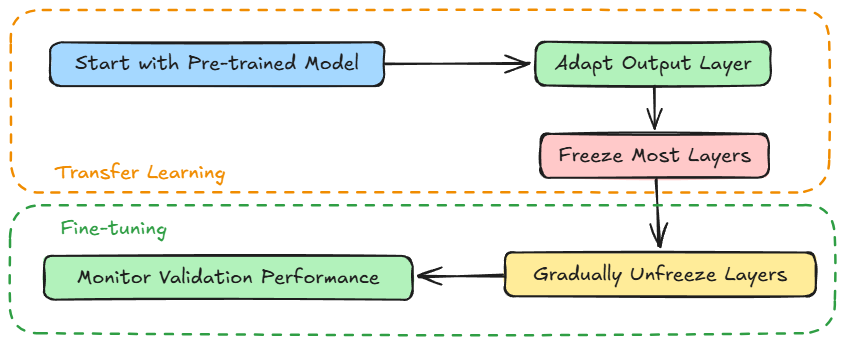
Typical transfer learning + fine-tuning pipeline
- Start from a pre-trained model
Example: ResNet pre-trained on ImageNet, or BERT pre-trained on large corpora. - Adapt the output layer(s)
Replace the classifier head to match your task (e.g.,1000 → 10classes, or a sentiment head with 2 outputs). - Freeze most layers at first
Train only the new head (or top few layers). This lets the new classifier align without disturbing the rich pre-trained representations. - Unfreeze some or all layers gradually
Do it with a much smaller learning rate, so the backbone weights are fine-tuned gently for the new task. - Monitor validation performance
Because the base model already learned good features, you usually need only a few epochs to adapt.
Note that:
- Steps 1–3 = transfer learning (feature extraction mode).
- Steps 4–5 = fine-tuning.
Let's illustrate fine-tuning with a practical example in code. Find the notebook attached below: