Model Development and Optimization: Fundamentals of Development and Hyperparameter Tuning
MLOps Part 8: A systems-first guide to model development and optimizing performance with disciplined hyperparameter tuning.
Recap
Before we dive into Part 8 of this MLOps and LLMOps crash course, let’s quickly recap what we covered in the previous part.
Part 7 concluded the discussion on the data and processing phase of the machine learning system lifecycle.
There, we explored Apache Spark for distributed data processing and Prefect for robust orchestration of ML pipelines.
We began by understanding the basics of Spark DataFrame and MLlib for ML pipelines through a practical hands-on example.

Next, we saw when exactly we should use Spark and how it differs from Pandas. Here, we understood the concept of lazy execution in Spark.

Finally, we explored orchestration concepts through a hands-on example using Prefect and took a comprehensive look at best practices for scheduling and pipeline management.
If you haven’t explored Part 7 yet, we strongly recommend going through it first, since it sets the foundations and flow for what's about to come.
Read it here:

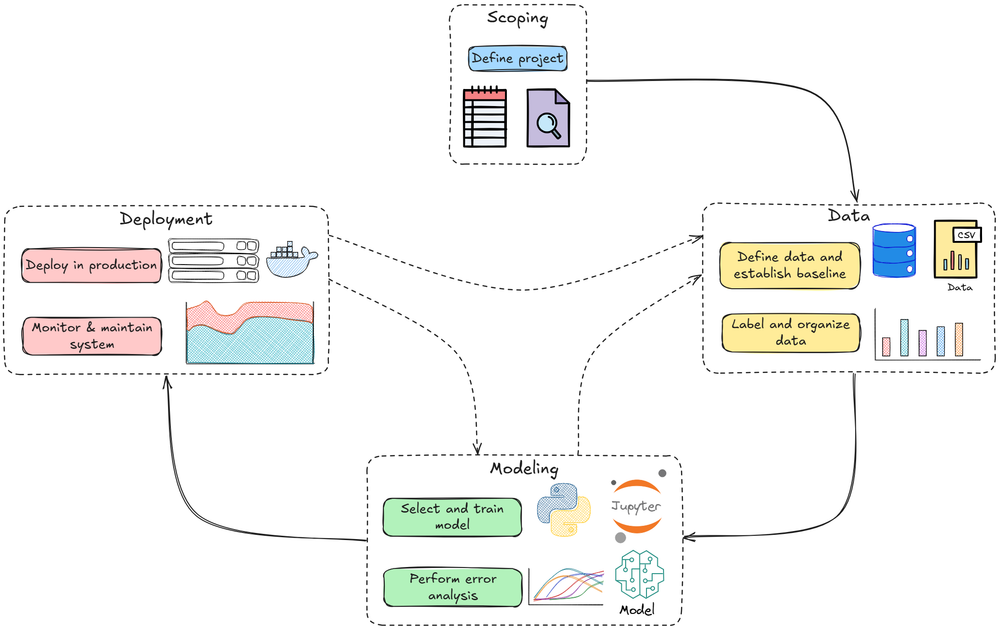
In this chapter, we'll move ahead and dive deep into the modeling phase of the MLOps lifecycle, discussing it from a systems perspective.
When developing machine learning models for production systems, the goal is not just to maximize accuracy on a leaderboard or validation set; it's to build models that perform well and run efficiently under real-world constraints.
Efficient model development means designing and training models with an eye on these operational concerns from the start. In this chapter, we will explore best practices for model development and optimization through an MLOps lens.
We'll cover:
- Model development fundamentals
- Phases of model development and deployment
- Debugging model training
- Optimization: Hyperparameter tuning
As always, every idea and notion will be backed by concrete examples, walkthroughs, and practical tips to help you master both the idea and the implementation.
Let’s begin!
Introduction
In production (e.g., a web service or mobile app), considerations like inference latency, throughput, memory footprint, and scalability become as important as raw predictive performance.
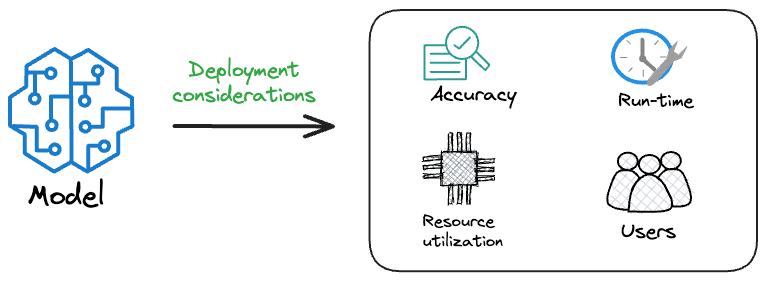
A model that’s 1% more accurate but twice as slow, too large or complex for the deployment environment, may be a poor choice in practice.
This shift in focus is central to MLOps: we need techniques to develop, optimize, and fine-tune models so they are not only accurate but also reliable, fast, simple, and cost-effective in production.
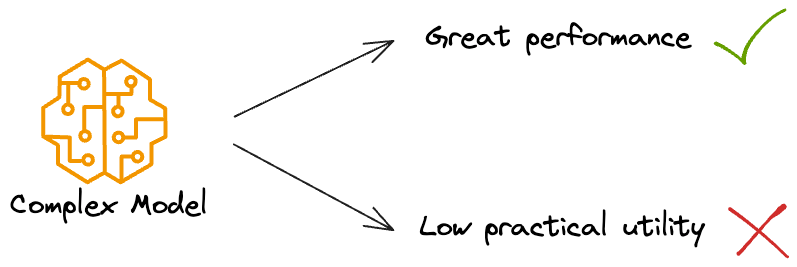
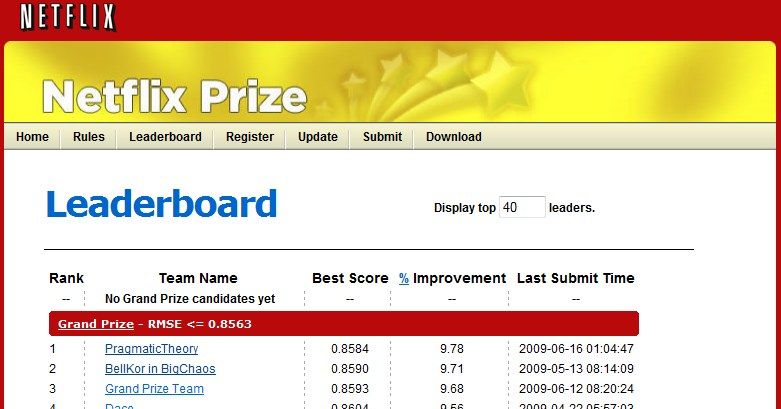
A famous real-life example comes from the Netflix Prize competition. The winning solution was an ensemble of many algorithms that achieved a 10% improvement in accuracy, yet Netflix never deployed it, since it was too complex and impractical to run at scale. Instead, a simpler approach that was easier to maintain and faster to serve users was preferred. This story is a constant reminder that as ML engineers, we must strike a balance between model complexity and practical utility.


Read it here:
With that mindset, let's begin by examining how to select and build models in a way that aligns with both ML objectives and production requirements.
Model development fundamentals
Developing an ML model is an iterative process of selecting an approach, training/evaluating, identifying improvements, and repeating until the model is good enough for deployment.
As discussed earlier, in an MLOps setting, good enough means not only achieving acceptable accuracy or error metrics but also meeting requirements for speed, memory, interpretability, and other constraints.
This section covers fundamental best practices for model development, including how to choose the right model for a problem, how to incrementally progress from simple to complex solutions, and what trade-offs to consider.
Tips for selecting and starting a model
Choosing the right model or algorithm is a critical first step. It's easy to be tempted by the latest state-of-the-art (SOTA) techniques, but the “best” model depends on context: data size, latency needs, development resources, etc.
Here are some things to keep in mind for effective model selection and initial development:
Avoid the “State-of-the-Art” trap
Don't assume the newest or most complex model is the best solution for your problem. Cutting-edge research models often show marginal gains on academic benchmarks at the cost of huge increases in complexity.
Such models may be slow, require enormous data, or be difficult to implement. Always ask: Do I really need a billion-parameter Transformer, or would a simpler approach suffice?
Often, tried-and-true methods are easier to deploy and plenty effective for the task at hand. Use SOTA models judiciously, and evaluate if their benefits truly justify the added complexity in a production setting.
Start with the simplest model
A guiding principle in both software and ML: simple is better than complex. Begin with a simple, interpretable model (e.g., linear regression or a small decision tree) as a baseline.
Simple models are easier to debug and deploy, and give you a quick reality check on your pipeline. For example, if a logistic regression on your dataset yields reasonable accuracy, it confirms your features contain signal.
This baseline also provides a benchmark: any more complex model should beat its performance to be worth the effort. Starting simple and then gradually increasing complexity helps you understand the impact of each change.
This approach helps catch problems early: if even a simple model performs far worse than expected (or worse than random chance), or conversely performs suspiciously well, it usually signals underlying data issues or flaws in the pipeline.
Avoid bias in model comparisons

When trying multiple algorithms, be fair in comparison. It's easy to spend more time tuning the model you’re most excited about or personally prefer, leading to a biased assessment of its performance.
To avoid this, aim to give each model equal attention and tuning effort to make objective, data-driven decisions. Be wary of human bias: an enthusiastic engineer might unintentionally get better results from one model simply by tinkering more with it.
Ensure comparable conditions, for example, use the same training/validation splits and evaluation metrics, and enough trials for each model type. Only then draw conclusions about which model family works best.
Consider present vs. future performance
The best model today may not be the best tomorrow as data grows or changes.
Some algorithms scale better with more data. For instance, a small dataset might favor a decision tree or SVM, but with 100x more data, a neural network might overtake in accuracy.
Moreover, if you expect data to grow, plan for that.
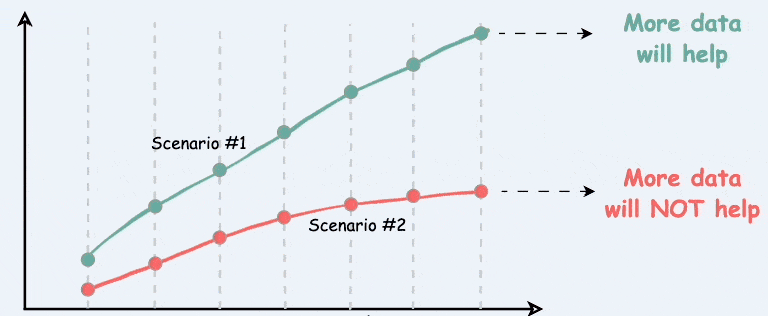
A good practice is to plot learning curves: model performance vs. training set size. If a model’s curve plateaus quickly, but another model’s performance keeps improving with more data, the other model may win in the long run when you have that additional data.
Also consider adaptability, i.e., will the model need to update frequently? If so, a model that can incrementally learn (online learning) or that trains faster might be preferable, even if its immediate accuracy is slightly lower.