Data and Pipeline Engineering: Sampling, Data Leakage, and Feature Stores
MLOps Part 6: A deep dive into sampling, class imbalance, and data leakage; plus a hands-on Feast feature store demo.
Recap
In Part 5 of this MLOps and LLMOps crash course, we explored the basics of the cornerstone of all machine learning systems: data and pipelines.
We began with an introduction to the data landscape in machine learning and explored why data and its processing are such important in the world of MLOps.

We then moved on to explore the different types of data sources important in production ML systems, such as user input data, system logs, internal databases, and third-party sources.
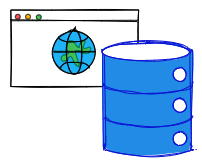
We also discussed various classifications of data sources, such as text vs. binary and row-major vs. column-major formats. We examined how they differ and the advantages and disadvantages of each.
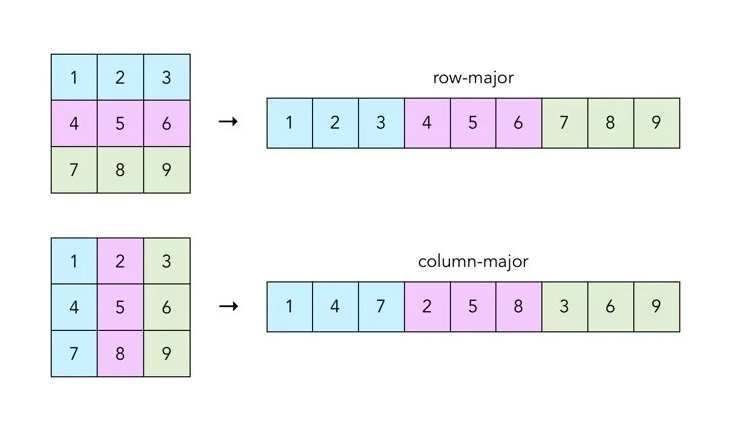
Next, we moved into the core conceptual focus of Part 5, which covered ETL and ELT pipelines. We explored both approaches and developed a clear understanding of how they differ while still complementing each other.
From there, we went hands-on. We walked through a detailed simulation of a hybrid ETL/ELT pipeline, simulating multiple data sources along with the extraction, validation, transformation, and loading stages.
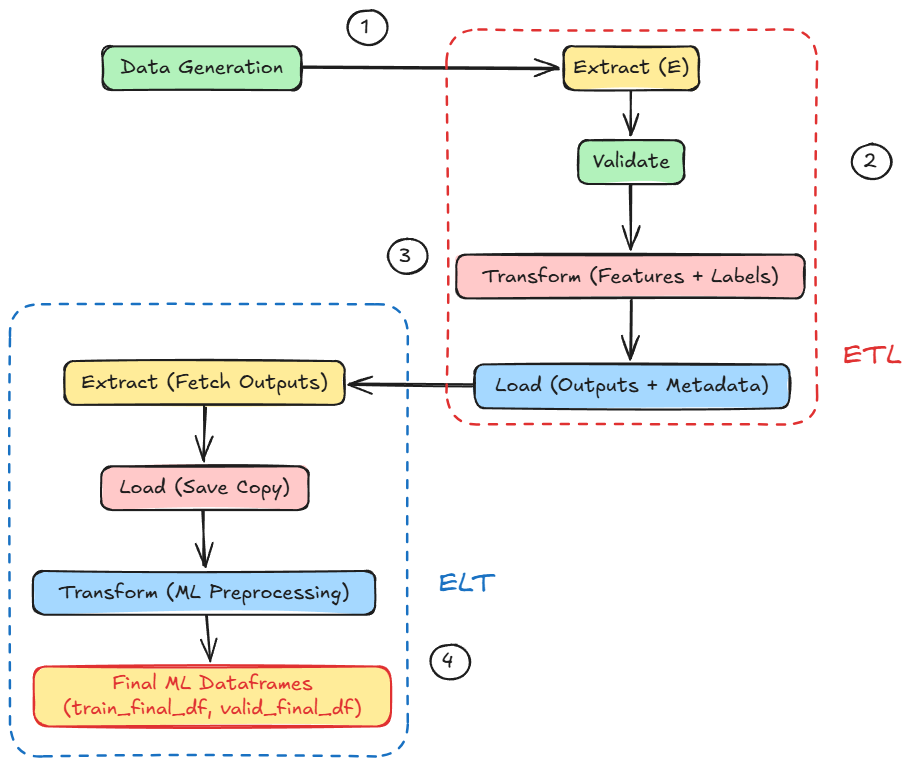
If you haven’t explored Part 5 yet, we strongly recommend going through it first since it lays the conceptual scaffolding and implementational understanding that’ll help you better understand what we’re about to dive into here.
You can read it below:

In this chapter, we’ll continue with data processing and management in ML systems, diving deeper into concepts and practical implementations.
We'll cover the blueprint, learning how to design and sample data specifically for machine learning, with a crucial deep dive into the treacherous pitfall of data leakage. We will then centralize our work in a feature store, the hub that ensures consistency between training and serving.
As always, every notion will be backed by concrete examples, walkthroughs, and practical tips to help you master both the idea and the implementation.
Let’s begin!
Sampling strategies
Sampling is the practice of selecting a subset of data from a larger pool. In machine learning, sampling occurs in many stages of the workflow:
- Choosing what real-world data to collect for building your dataset.
- Selecting a subset of available data for labeling or training (especially when you have more data than you can feasibly use).
- Splitting data into training/validation/testing sets.
- Sampling data during training for each batch (in stochastic gradient descent, for example).
- Sampling in monitoring (e.g., logging only a fraction of predictions for analysis).
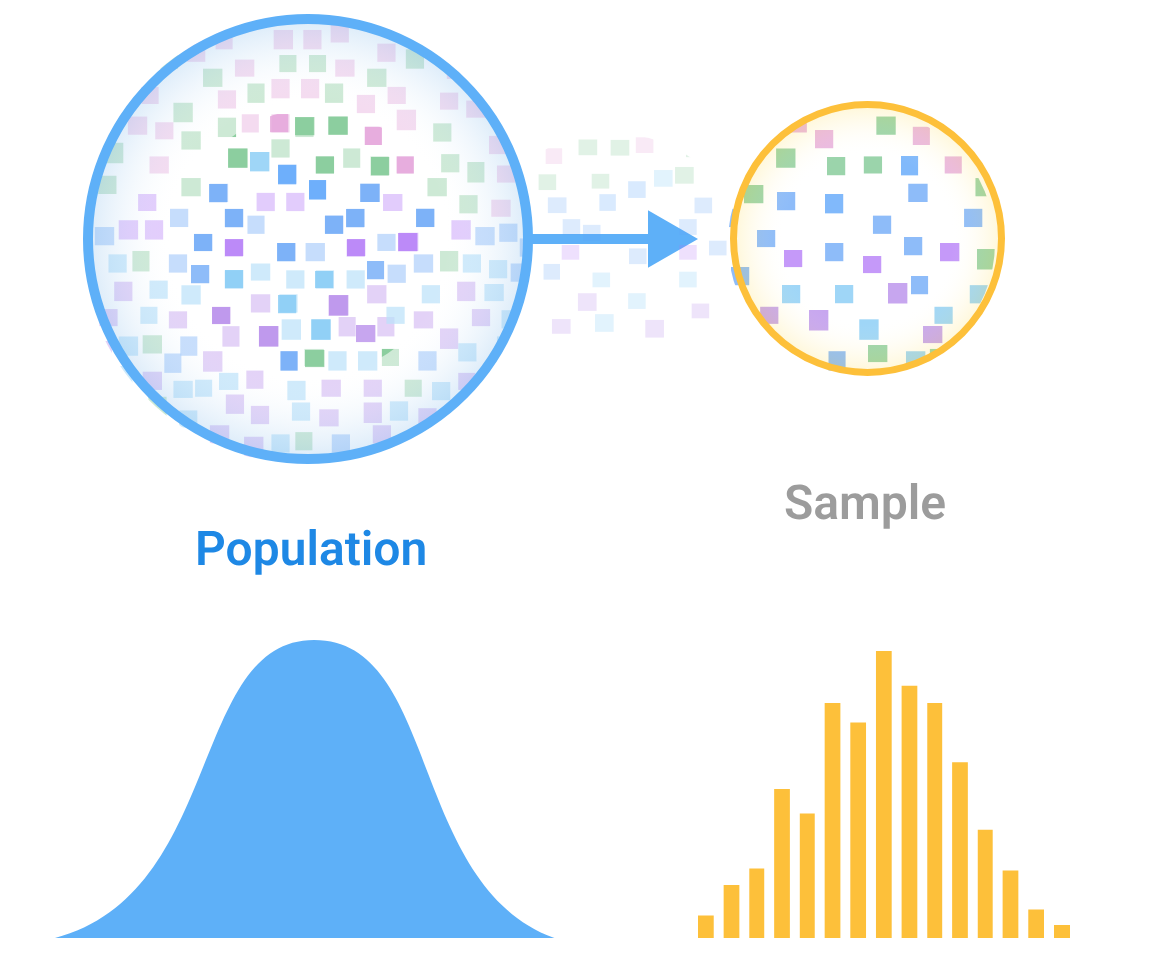
For most, the common exposure to sampling is likely the train/validation/test split. But it’s important to realize that how you sample can introduce biases and affect model performance.
Why sampling matters?
In many cases, we cannot or do not use all available data. Perhaps data is too large (training on trillions of records isn’t feasible), or obtaining labels is costly, so we label a subset, or we intentionally down-sample for quicker experimentation.
And it must be obvious that good sampling can make model development efficient and ensure the model generalizes, while poor sampling can mislead your results.
For example, selecting an unrepresentative subset can cause your model to perform well on that particular subset but fail in production.
Types of sampling
Broadly, sampling methods fall into two families:
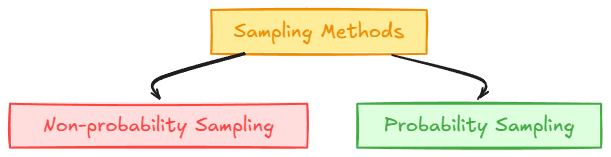
- Non-probability sampling: Not strictly based on random chance but uses some subjective or practical criteria to pick data.
- Probability sampling: Every data point in the population has some probability of being selected, typically striving for an unbiased sample.
Let’s look at common techniques in each category and their implications:
Non-probability sampling methods
Under non-probabilistic methods for sampling, we have:
Convenience sampling
Selecting data that is easiest to obtain. For example, using the first 10,000 records from a log because they’re readily at hand, or using a dataset collected from one accessible source (like one city or one user group) because it’s convenient.
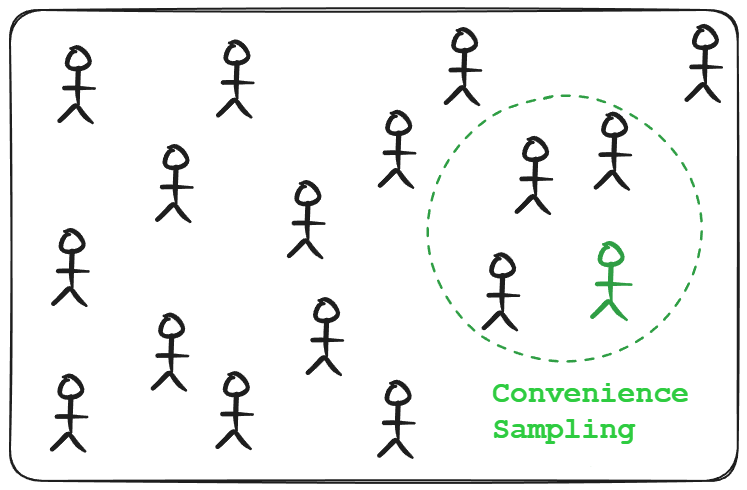
Implications of this method include a high risk of bias since the sample may not represent the overall population.
This method is popular because, as the name says, it’s convenient, but it can skew results. For example, a model trained on data from a single city may not generalize to other regions.
Snowball sampling
Using existing sample data to recruit further data. This is often used in social networks or graphs. For example, you have data on some users, then you include their friends, then friends-of-friends, and so on.
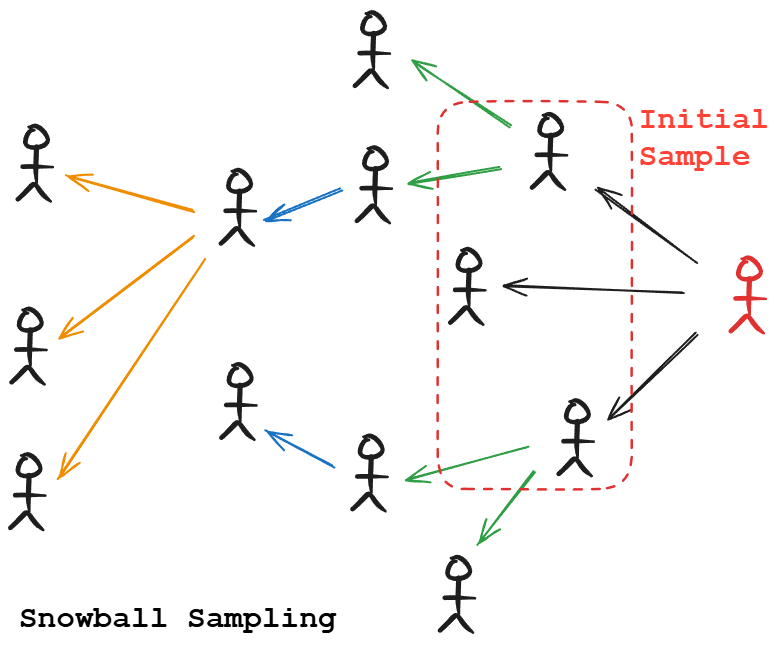
This can be helpful to gather relevant data when you don’t have direct access, but it can over-represent tightly connected communities and miss out on isolated samples.
Judgment (purposive) sampling
Relying on experts to hand-pick what data to include.
For instance, a domain expert might select “important” cases to train on. This can incorporate valuable domain knowledge, but it’s subjective and can reflect the expert’s biases.
Quota sampling
This sampling technique ensures certain predefined quantities or a fraction of different sub-groups. For example, you may decide to include exactly 100 samples of each class in a classification problem, or maintain a specific count or certain ratio of categories.
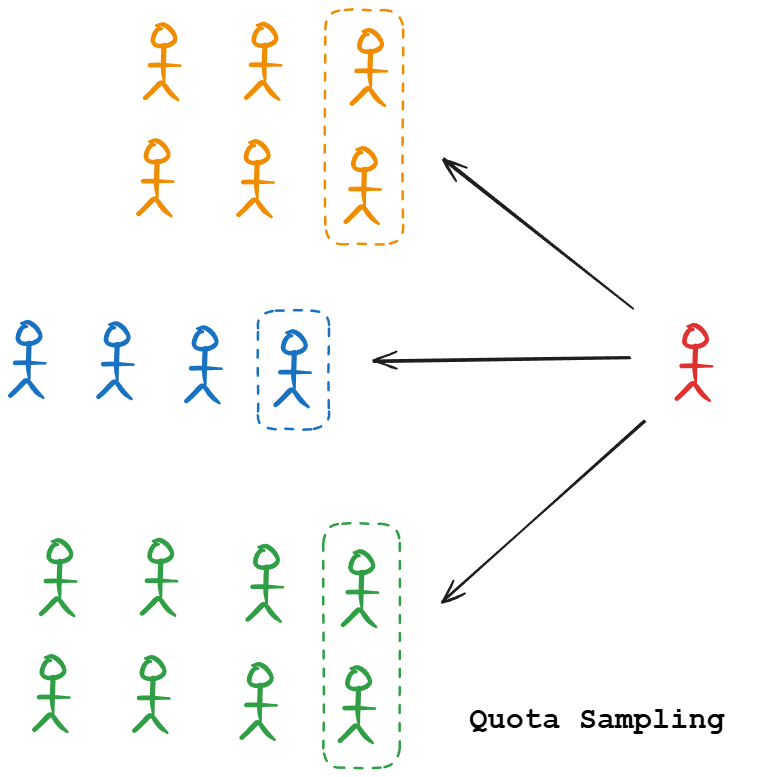
This guarantees representation of all groups, but the selection within each group might still be non-random (usually convenience-based within each quota).
Quota sampling can introduce bias if the population within each quota is not homogeneous.
Non-probability sampling is often a starting point (especially in early prototyping or when data access is limited). However, models built on non-random samples may not be reliable.
If you use these methods, be aware of the biases. For example, convenience sampling might be acceptable for a quick experiment, but before deploying a model, you’d want to retrain it on a more representative sample.
Probability (random) sampling methods
Probabilistic sampling methods are less prone to bias than non-probabilistic methods, owing to the inherent randomness in their selection strategy. The main techniques under this category include:
Simple random sampling
Each data point has an equal chance of being selected. This is the ideal basic approach, like shuffling your dataset and picking a subset. It works well if your data is homogeneous or you truly have no prior knowledge of important groupings.
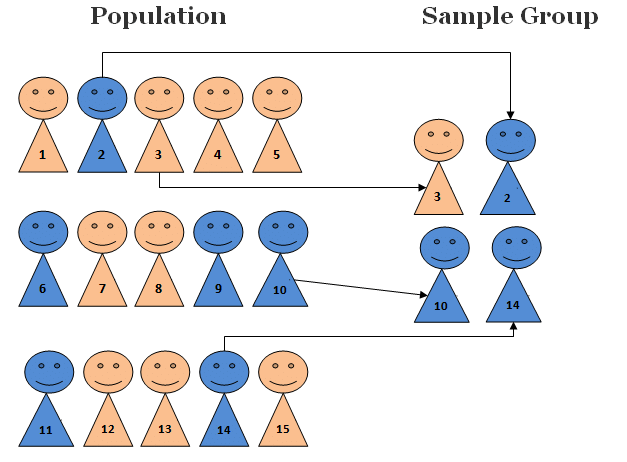
However, simple random sampling can be problematic if there are rare but important subgroups; you might, by chance, pick too few of them.
Example: You have a dataset of transactions, and 2% are fraud. A simple random sample of 1,000 might contain around 20 fraud cases. If you happen to get 5 or 50 by random fluctuation, your sample’s fraud rate would skew.
This disadvantage leads to methods like weighted sampling and stratified sampling.
Weighted sampling
A form of random sampling where each sample is given a weight (probability) for selection. This allows oversampling certain cases or undersampling others in a controlled way.
For instance, you might weight rare classes higher so they appear more in the sample. Tools like random.choices in Python allows weighted sampling.
In ML training, weighted sampling might be used to combat class imbalance (oversampling minority class) or to emphasize recent data more than older data, etc.
The concept of sample weights during model training is related but distinct: weighted sampling picks more of some data to include, whereas sample weights let you include all data but give some examples more importance in the loss function.
Both aim to handle imbalance or importance, but weighted sampling physically changes the dataset composition.
Stratified sampling
Here, you divide the population into strata (groups) and sample from each group separately to ensure representation.
For an imbalanced classification, you might stratify by class label so that your sample has the same class proportions as the full dataset (or ensure each class gets enough representation).
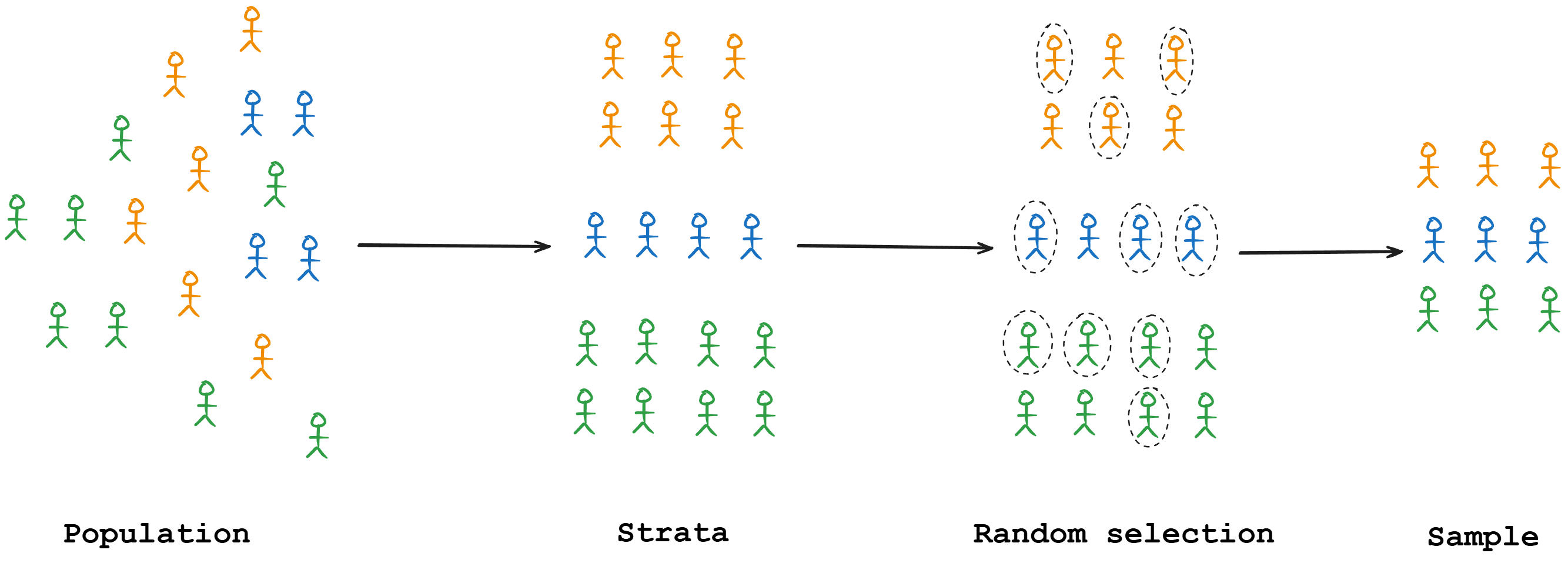
Stratified sampling greatly reduces variance between subgroup representation and is generally recommended for creating train/test splits when class distributions are important.
The drawback is that you need to know the important grouping variables upfront, and if some groups are very small or hard to stratify (e.g., continuous variables), it might not be applicable.
Reservoir sampling
This is an algorithm for sampling from streaming data of unknown size, ensuring each item has an equal probability of being included.
It is useful when you have a continuous stream (say, user clicks) and you want to maintain a random sample of fixed size (like the last 1,000 clicks, but in a random sense, not just the latest).
A reservoir sampling strategy allows you to sample from a stream without storing it all, which is crucial in production streaming pipelines.
Importance sampling
A more advanced technique often used in statistical estimation and reinforcement learning. In importance sampling, you want to evaluate or train on a distribution that is different from where your data came from by re-weighting samples.
In ML pipelines, importance sampling can be used to bias the sampling towards informative cases while still correcting for that bias during estimation.
For example, in reinforcement learning, you might sample episodes from a behavior policy but want to evaluate a target policy. Importance sampling provides a way to correct for the difference.
Practical implications of sampling choices
Given the critical role sampling plays in shaping the downstream stages of an ML system, it is essential to understand the key implications that arise directly from sampling choices.