Model Deployment: Cloud Fundamentals
MLOps Part 13: An overview of cloud concepts that matter, from virtualization and storage choices to VPC, load balancing, identity, and observability.
Recap
Before getting into Part 13 of this crash course, let’s quickly recap what we covered in the last part.
In Part 12, we explored key aspects of the deployment and monitoring phase of the MLOps lifecycle, focusing on container orchestration and deployment using Kubernetes.

We began by exploring the foundational concepts essential for understanding Kubernetes. This included learning about container images and containers, the microservices architecture, service meshes, and the principles of immutable infrastructure.
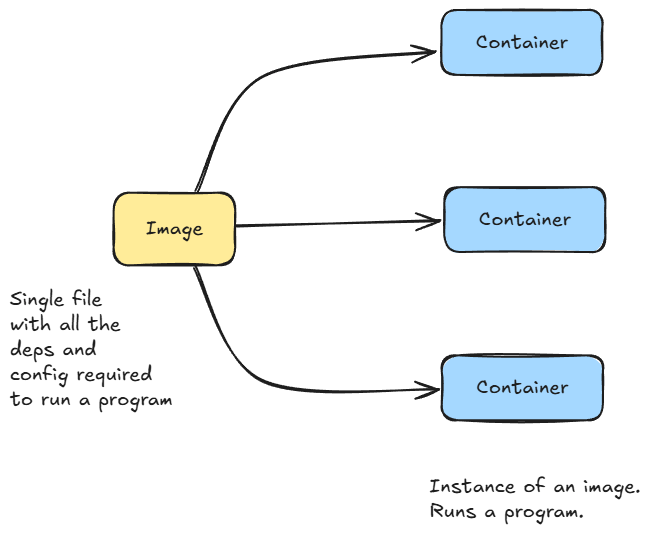
After that, we introduced Kubernetes, understood why exactly we need it, and what exactly it could help us with.
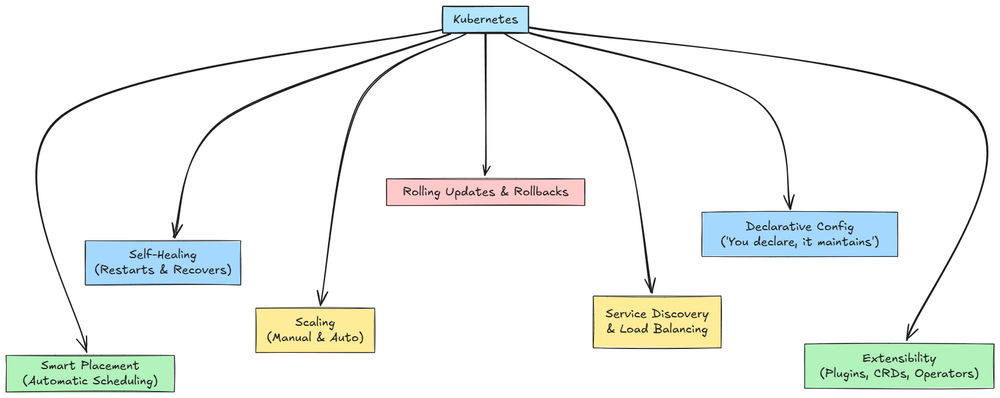
Next, we dived into the architecture and core concepts of Kubernetes. This included understanding clusters, the control plane, nodes, and the key terminologies and components associated with each of these units.
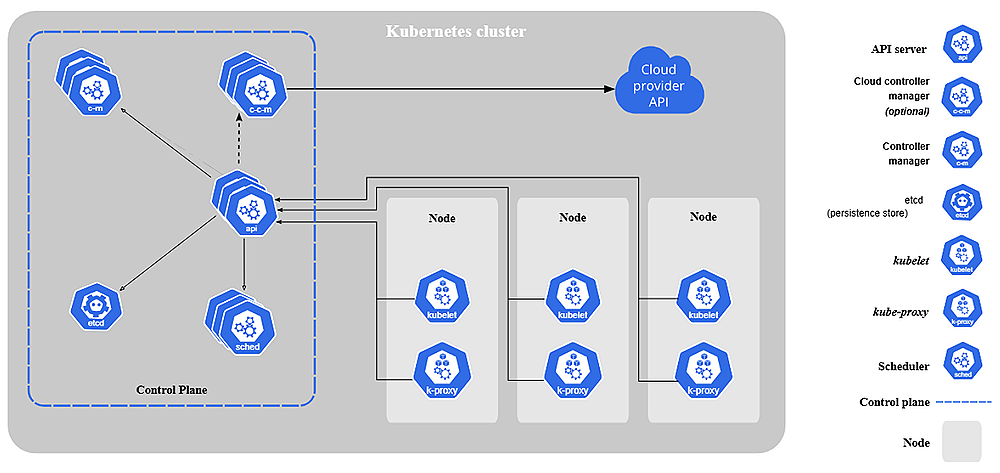
Moving ahead, we explored how different components in Kubernetes interact with each other and form workflows and control loops (desired state → actual state → reconciliation).
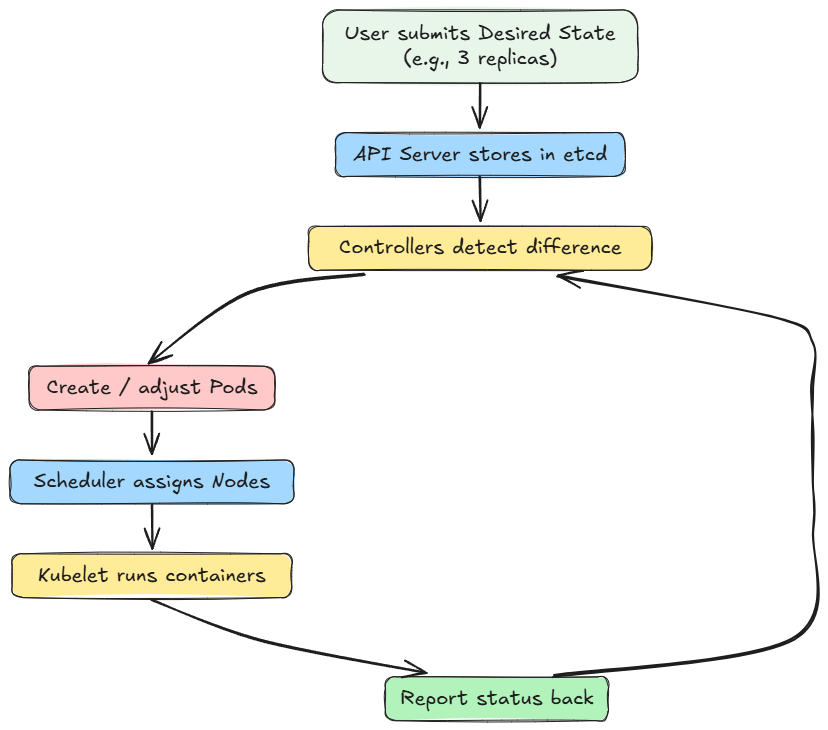
We also explored key operational features of Kubernetes, including service discovery, routing, rolling updates, failure handling, and autoscaling in brief.
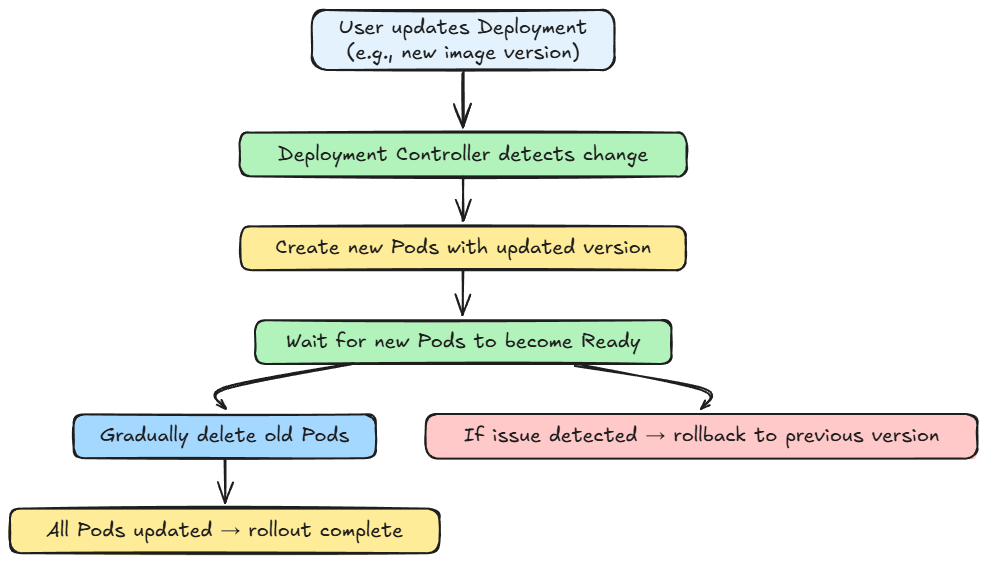
Finally, we went hands-on, understanding how exactly we orchestrate and deploy our containerized application with Kubernetes, in a local setup.
If you haven’t explored Part 12 yet, we strongly recommend going through it first since it lays the conceptual scaffolding that’ll help you better understand what we’re about to dive into here.
Read it here:

In this chapter, we’ll continue our discussion on the deployment phase, diving deeper into important concepts, specifically cloud.
We'll cover the core cloud computing concepts, agnostic of any specific vendor (for now, at least).
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let’s begin!
Basics: how the internet works
Every cloud solution is built on fundamental networking principles. Let's discuss the most fundamental ones, briefly and abstractly:
IP Addresses and domain names
Every device connected to the internet requires an IP address. We primarily deal with two types: IPv4 and IPv6.
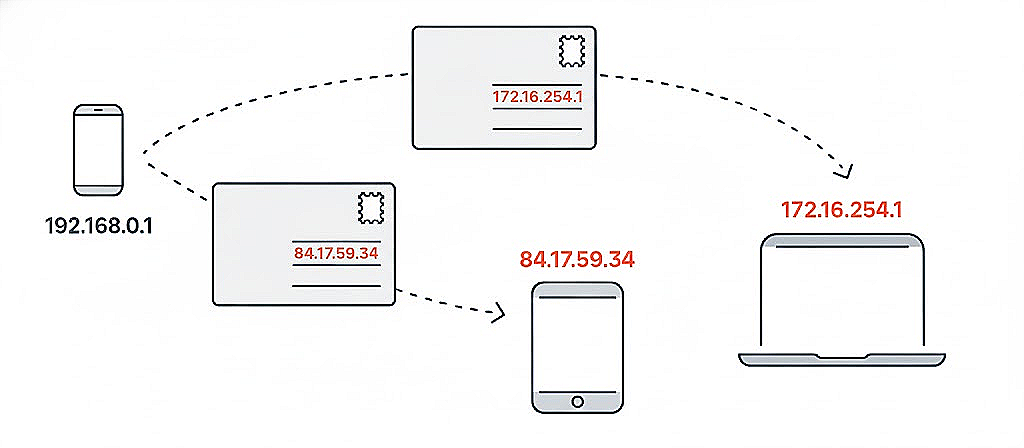
IPv6 was created because IPv4 addresses were running out as the Internet grew.
Since humans are not good at remembering long numbers, we use domain names instead.
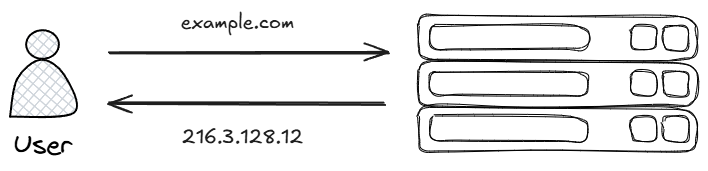
This is where DNS (Domain Name System) comes in, which converts user-friendly domain names into the numerical IP addresses that computers understand.
Data movement
When you load a website or send an email, data doesn't move as one big chunk. Your information is broken down into small pieces called packets.
Each packet carries the data itself, along with crucial information like the destination IP and the source IP.

The system managing this transfer is TCP/IP. TCP handles breaking down the data and ensuring it arrives correctly, while IP ensures the packets reach the right destination.
Cloud computing: definition and characteristics
Cloud computing refers to delivering computing services (e.g., servers, storage, databases, networking, software, analytics) over the internet (“the cloud”), enabling users and organizations to access them on demand.
Rather than owning physical hardware, organizations can rent virtualized resources, scale them elastically, and pay only for what they use.
The idea traces back to time-sharing and virtualization in the 1960s and ’70s. More recently, cloud providers such as AWS, Azure, and Google Cloud made on-demand services scalable and accessible to developers and enterprises.
NIST essential characteristics

According to NIST (National Institute of Standards and Technology), any cloud system should exhibit the following five essential characteristics:
- On-demand self-service: Users can provision computing capabilities (e.g., server time, storage) on their own without requiring interaction with the provider’s staff.
- Broad network access: Services are accessible over the network via standard mechanisms (e.g., HTTP, APIs) from heterogeneous client platforms (laptops, mobiles, etc.).
- Resource pooling/multi-tenancy: The provider’s resources are pooled to serve multiple consumers, dynamically assigning and reassigning resources (e.g., CPU, memory, storage) based on demand.
- Rapid elasticity/scalability: Capabilities can be elastically scaled up or down to meet fluctuating demands; to the consumer, the available resources seem unlimited.
- Measured service (metering): Resource usage is monitored, controlled, and reported, enabling pay-per-use or chargeback models.
To read about it in more detail, you can check out the attached official publication from NIST:
These characteristics help distinguish cloud computing from traditional hosting or fixed-capacity infrastructure.
Cloud computing: types of models
In the context of cloud computing, a model refers to a structured approach to how cloud services are delivered, deployed, billed, etc.
These models help organizations choose the right combination of flexibility and control based on their needs.
Let's explore the different types of cloud computing models that influence how cloud resources are consumed, how they are paid for, and how responsibilities are divided:
Deployment models
Cloud deployment refers to how cloud services are provided to end users. Common models include:
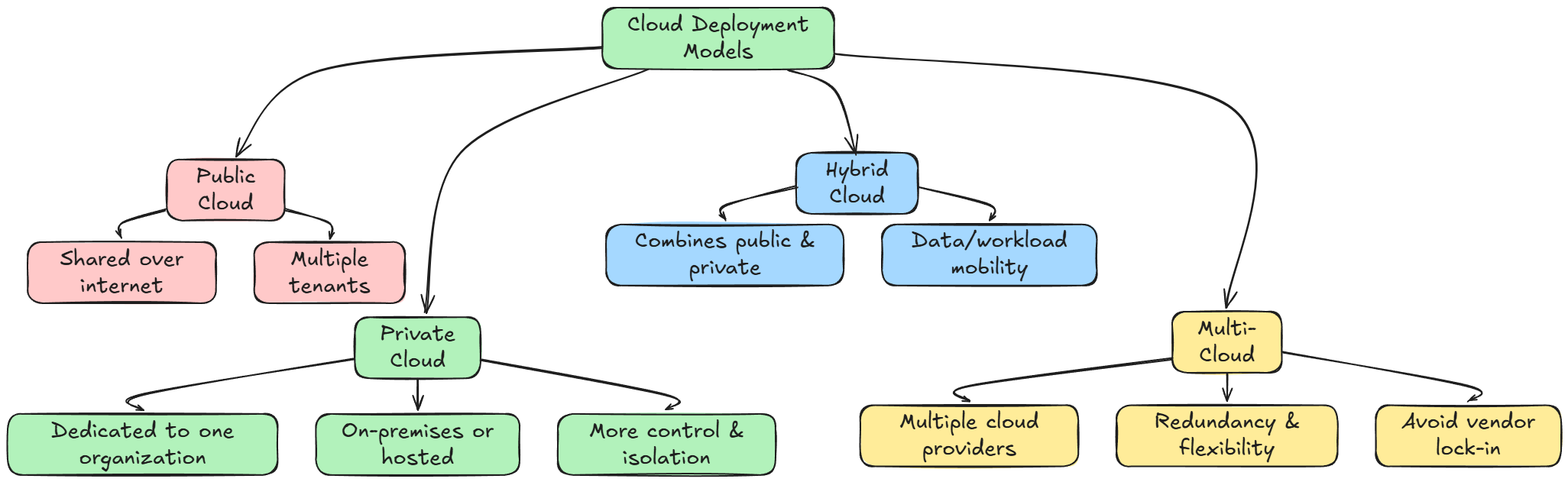
- Public cloud: Services are offered over the public internet and shared among multiple tenants.
- Private cloud: Infrastructure dedicated to a single organization (on-premises or hosted), offering more control and isolation.
- Hybrid cloud: A combination of public and private clouds, allowing data/workloads to move between both environments.
- Multi-cloud: Using multiple cloud providers for redundancy, best-of-breed services, or avoiding vendor lock-in.
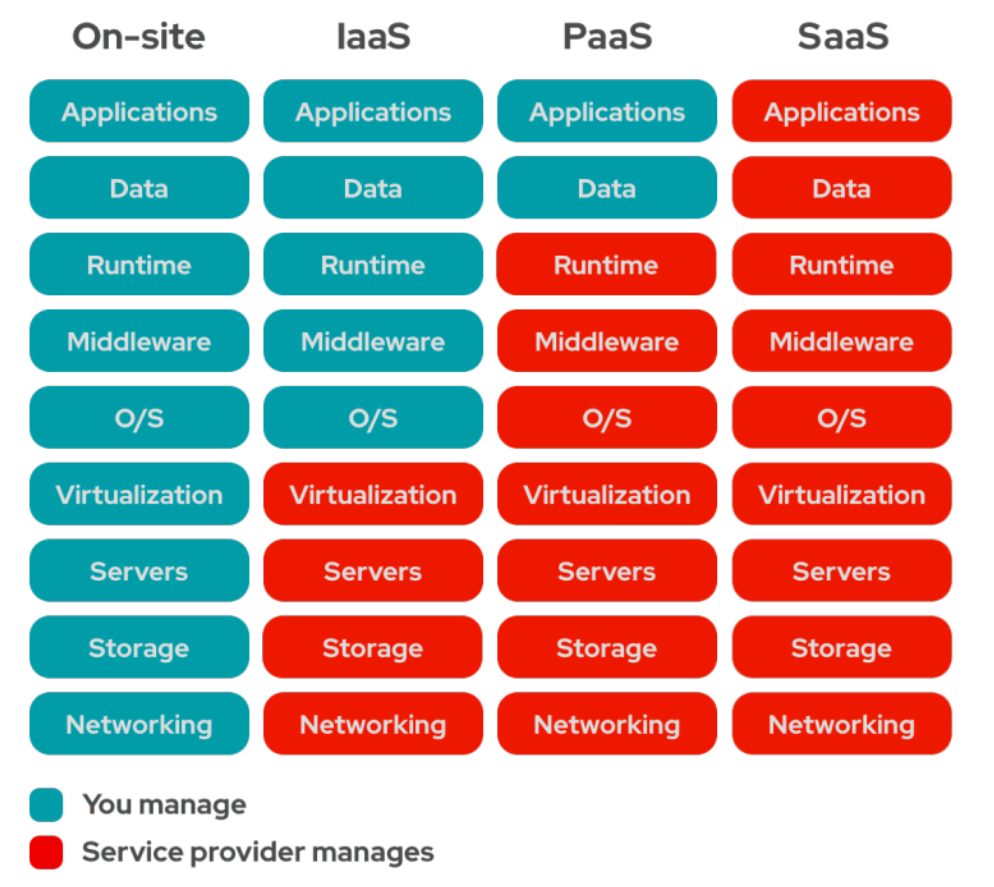
Service models: IaaS, PaaS, SaaS
Service models describe how much abstraction the cloud provider handles versus what the user must manage.
- Infrastructure as a Service (IaaS): Users provision virtual machines, storage, networks, and other fundamental resources, and must manage OS, runtime, and applications. The provider handles virtualization, physical infrastructure, and basic networking.
- Platform as a Service (PaaS): Users deploy applications using provider-managed runtimes, middleware, and operating systems. The provider handles scaling, patching, and much of the infrastructure plumbing.
- Software as a Service (SaaS): Fully managed applications that the user can consume without worrying about underlying infrastructure (e.g., Gmail).
The diagram below effectively summarizes the above-discussed characteristics:
Cloud economics & cost models
One of the central attractions of cloud is cost model flexibility:
- Pay-as-you-go: Users pay for actual usage (compute hours, storage size, network in/out).
- Reserved/committed capacity: Discounts for committing to use resources over a period.
- Spot/preemptible instances: Very low-cost compute nodes that can be reclaimed (ideal for training or batch workloads).
- Cost leakage & overprovisioning: Without good governance, unused resources or idle services can accumulate costs.
A good mental model is: cloud resources = utility resources (like electricity). You want to scale dynamically and only pay for what you use.
Shared responsibility model
In the cloud, security and operational responsibilities are shared between the provider and the user. The precise boundaries differ by service model (IaaS, PaaS, SaaS).
Typically:
- The provider ensures physical infrastructure, network, host OS, and hypervisor security.
- The user handles secure configuration of the OS, network rules, application logic, data encryption, IAM, and compliance.
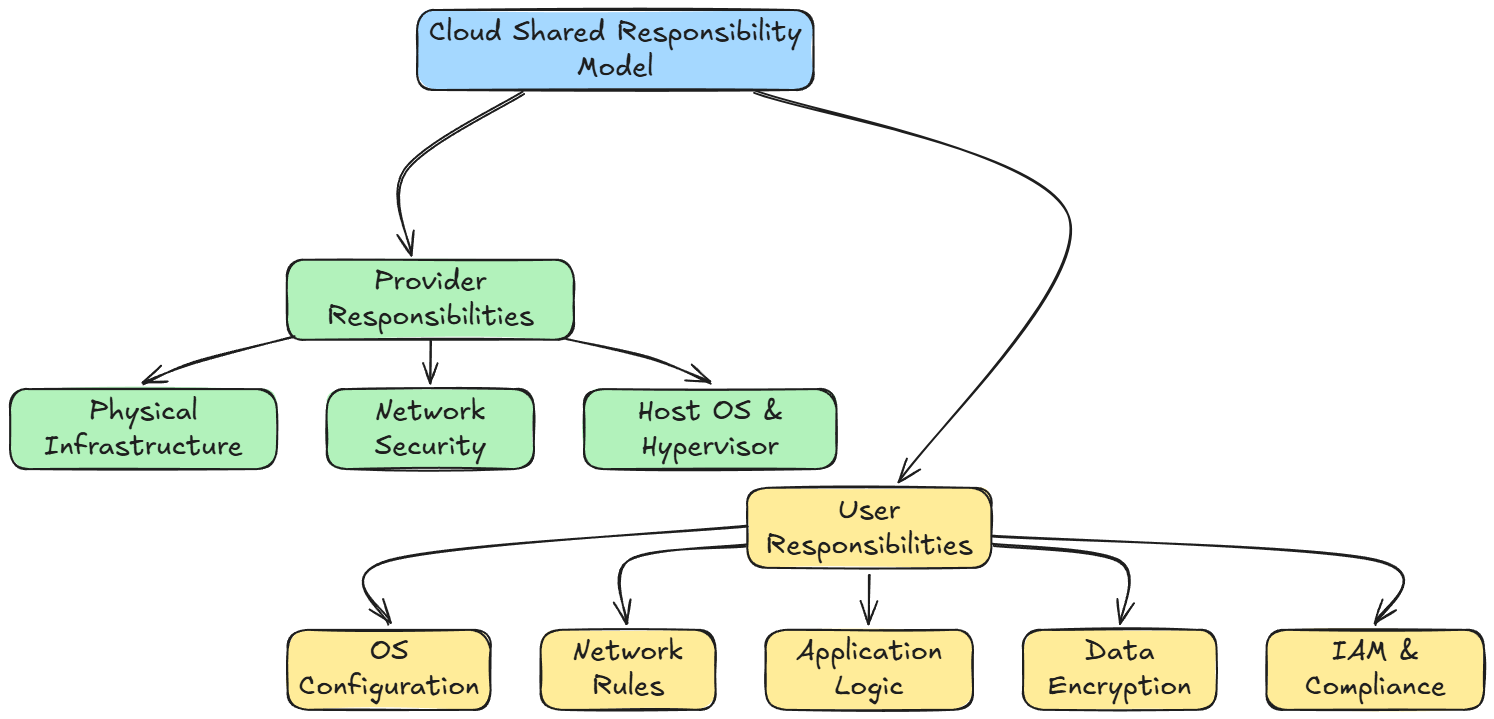
Understanding which side is responsible for which layer is critical to avoid gaps.
Now that we have understood the different models, let's go ahead and study the different cloud infrastructure components.
Cloud infrastructure components
Let’s enumerate the fundamental building blocks of the cloud:
- Compute: Virtual machines, containers, serverless runtimes, GPU/TPU instances
- Storage & data layer: Object storage, block storage, file systems, data lakes
- Networking: Virtual private network, subnets, routing, NAT, ingress, load balancers
- Identity & Access Control: IAM roles, groups, policies
- Monitoring & observability: Metrics, logs, traces, dashboards
- Security & compliance: Encryption, network segmentation, auditing
Virtual Machines, hypervisors, and virtualization
At the core of modern cloud computing lies virtualization, the process of creating a virtual version of something, such as a server, storage device, or network resource.
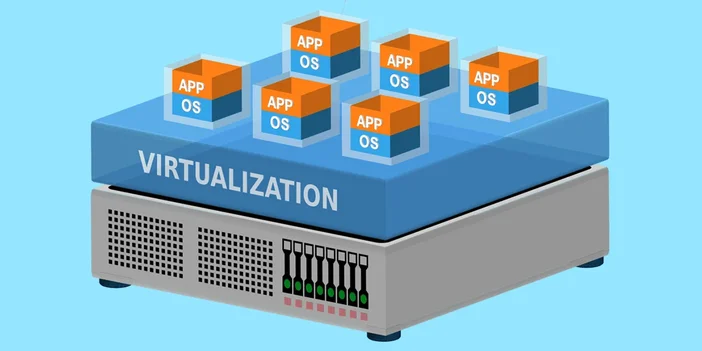
Virtualization enables multiple isolated computing environments to coexist on a single physical machine.
Hypervisor
A hypervisor, also known as a Virtual Machine Monitor (VMM), is the software (or firmware) layer that sits between the physical hardware and virtual machines.
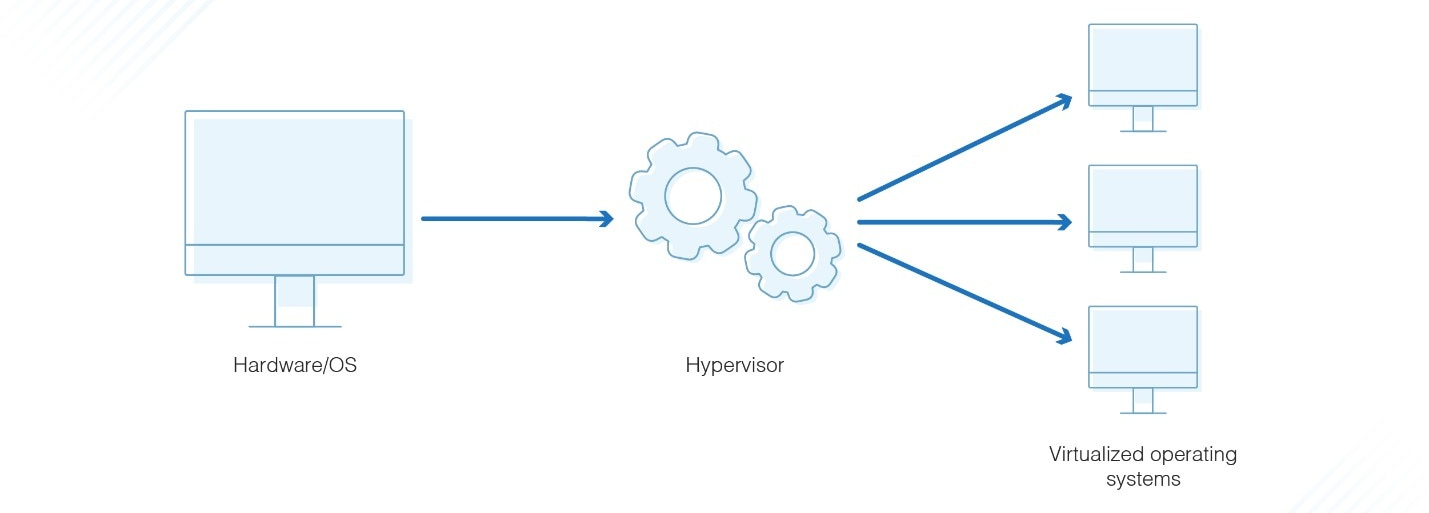
Its primary role is to abstract the physical hardware and allocate computing resources (CPU, memory, disk, and network) to multiple virtual machines (VMs).
There are two main types of hypervisors:
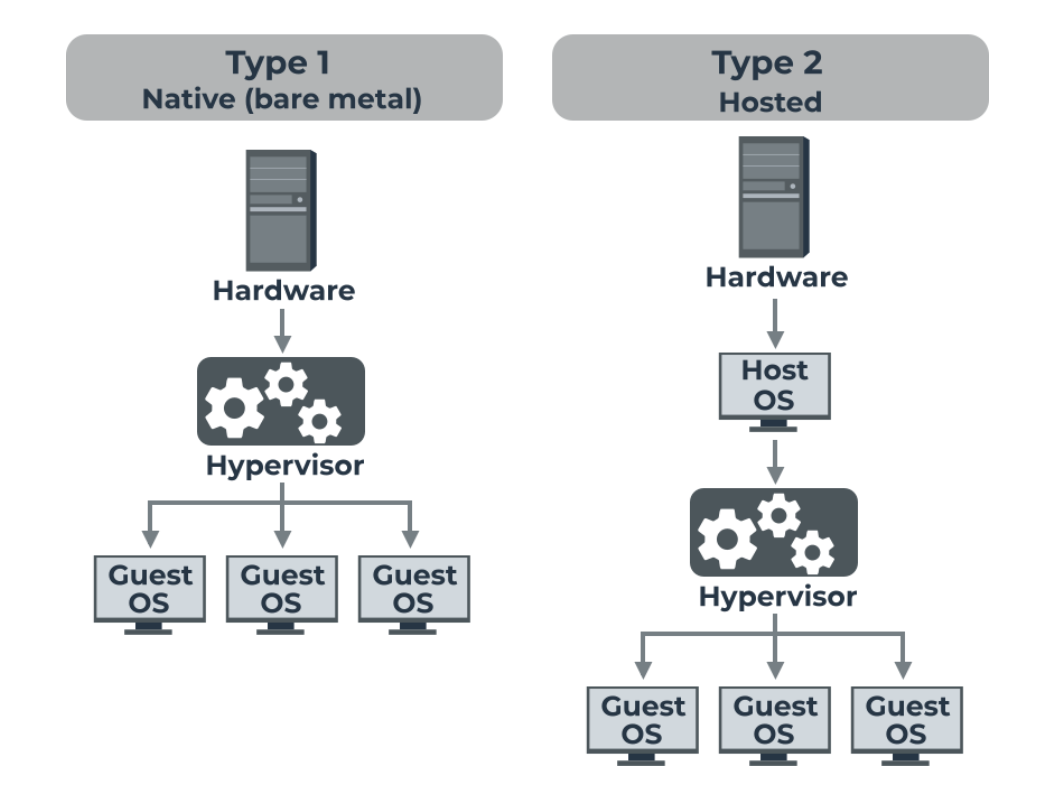
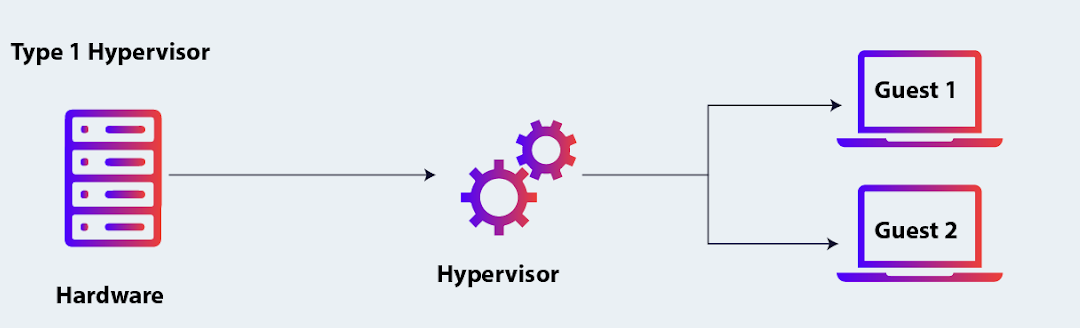
- Type 1 (Bare-metal Hypervisors): These run directly on the host's hardware and manage guest operating systems without a host OS. Examples include:
- VMware ESXi
- Microsoft Hyper-V
- KVM (Kernel-based Virtual Machine)
- Xen
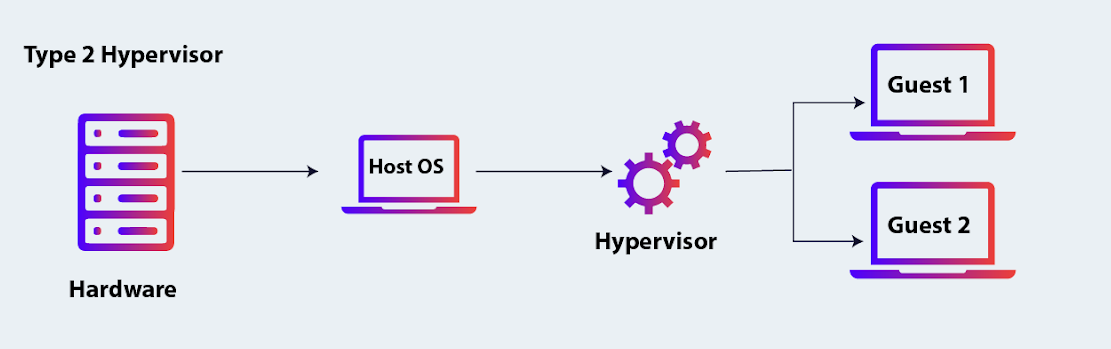
- Type 2 (Hosted Hypervisors): These run on top of a host operating system, just like any other application. Examples:
- Oracle VirtualBox
- VMware Workstation
- Parallels Desktop
How virtual machines work
A Virtual Machine is a complete emulation of a physical computer.
It includes:
- Virtual CPU (vCPU): Emulates physical CPU cycles allocated from the host.
- Virtual Memory: Allocated from the host’s RAM.
- Virtual Storage: Uses disk images to emulate storage.
- Virtual Network Interface: Connects to the virtual or physical network.
Each VM runs its own full operating system (guest OS), which is independent from others.
This allows for a strong isolation between VMs and the ability to run different OS types on the same hardware (e.g., Linux VM on Windows host).
Virtualization in the Cloud
Cloud providers (AWS, Azure, Google Cloud) use virtualization extensively to offer compute resources on demand. These resources are abstracted into instance types.
Instance types
An instance type is essentially a predefined VM configuration with specific resources:
For example, in AWS EC2:
t3.micro: 2 vCPU, 1 GiB RAM (burstable)m5.large: 2 vCPU, 8 GiB RAM (general purpose)c5.xlarge: 4 vCPU, 8 GiB RAM (compute-optimized)
Cloud users choose an instance based on workload needs: memory-intensive, compute-heavy, or storage-optimized.
Benefits of VMs and virtualization
- Isolation: Each VM is sandboxed; failures or security breaches in one VM don’t affect others.
- Resource allocation: Physical resources are efficiently shared and allocated dynamically.
- VM migration: VMs can be moved between physical hosts with minimal downtime (live migration).
- Snapshot & cloning: Easy to create snapshots or clone VMs for backup and scalability.
- Multi-tenancy: Enables multiple users or businesses to share the same physical infrastructure securely.
Limitations of VMs
While powerful, VMs are not lightweight:
- Overhead: Each VM runs a full OS, consuming CPU, memory, and storage.
- Boot time: VMs typically take longer to boot compared to containers.
- Resource waste: Unused allocated resources in a VM still count as in-use, reducing efficiency.
- Limited scalability speed: Spinning up or scaling VMs is slower than container-based deployments.
Due to these issues, containers are often preferred since they can run in a more lightweight manner compared to VMs.
Containers & orchestration (Kubernetes)
We have already covered Docker and Kubernetes in detail in previous chapters.

Here’s how they fit in the cloud:
- A container is a lightweight packaging of the application + dependencies, running isolated but sharing the host OS kernel.
- Kubernetes is an orchestration layer that schedules containers (pods), handles scaling, rolling updates, service discovery, and more.
- In cloud environments, Kubernetes often runs on VMs or managed container services.
Managed container services (EKS, GKE, AKS)
Rather than manually deploying and managing the Kubernetes control plane, cloud providers offer managed Kubernetes services:
- Amazon EKS: AWS’s managed Kubernetes service.
- Google GKE: Google Cloud's managed Kubernetes service.
- Azure AKS: Microsoft Azure's managed Kubernetes service.
These services offer reliability, control-plane maintenance, autoscaling, integration with cloud tooling, and more.
Storage systems: Block, Object, File
Workloads require different types of data storage:
- Object storage (e.g. AWS S3, Azure Blob, GCS): Stores blobs with metadata, highly durable and scalable.
- Block storage: Virtual disks that behave like raw disks (EBS in AWS). Useful for fast, persistent storage attached to compute nodes.
- File storage/shared file systems: Network file systems (e.g., EFS, NFS) that support file semantics and shared access.
- Databases/data warehouses: For structured data, metadata, etc.
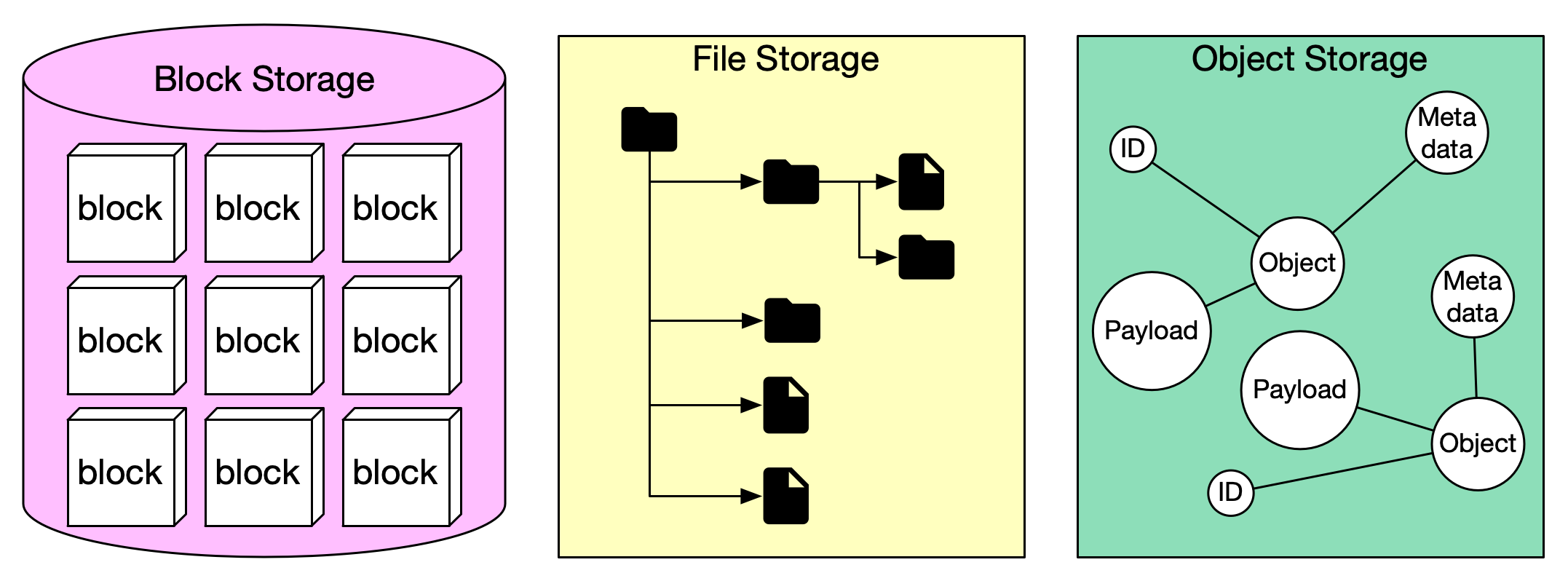
Choosing the right layer depends on throughput, access patterns, concurrency, and cost.
Let’s expand each storage type and the reasoning behind choosing them, focusing on their architecture, use cases, and trade-offs:
Object Storage
Cloud object storage, such as Amazon S3, Azure Blob Storage, or Google Cloud Storage, is built for handling massive amounts of unstructured data. Unlike traditional file or block storage, it organizes data as objects, not files within folders or sectors on disks.
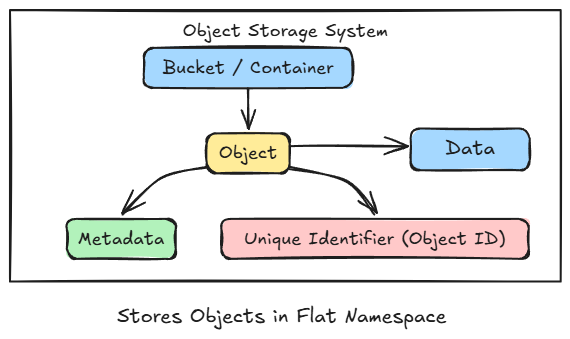
Each object contains three key components: