Background and Foundations for ML in Production
MLOps Part 1: An introduction to machine learning in production, covering pitfalls, system-level concerns, and an overview of the full ML lifecycle.
Introduction
So, you've trained your machine learning model and tested its inference capabilities.
What comes next?
Is your job done?
Not really.
What you’ve completed is only a small part of a much larger journey that will unfold next.
If you plan to deploy the model in a real-world application, there are many additional steps to consider. This is where MLOps becomes essential, helping you transition from model development to a production-ready system.
Machine Learning Operations (MLOps) in production is about integrating ML models into real-world software systems. It’s where machine learning meets software engineering, DevOps, and data engineering.
The goal is to reliably deliver ML-driven features (like recommendation engines, fraud detectors, voice assistants, etc.) to end-users at scale.
Hence, as mentioned earlier, a key realization is that the ML model or algorithm itself is only a small part of a production ML system.
In real-world deployments, a lot of “glue” is needed around the model to make a complete system, including data pipelines, feature engineering, model serving infrastructure, user interfaces, monitoring, and more.
Only a tiny fraction of an “ML system” is the ML code; the vast surrounding infrastructure (for data, configuration, automation, serving, monitoring, etc.) is much larger and more complex.
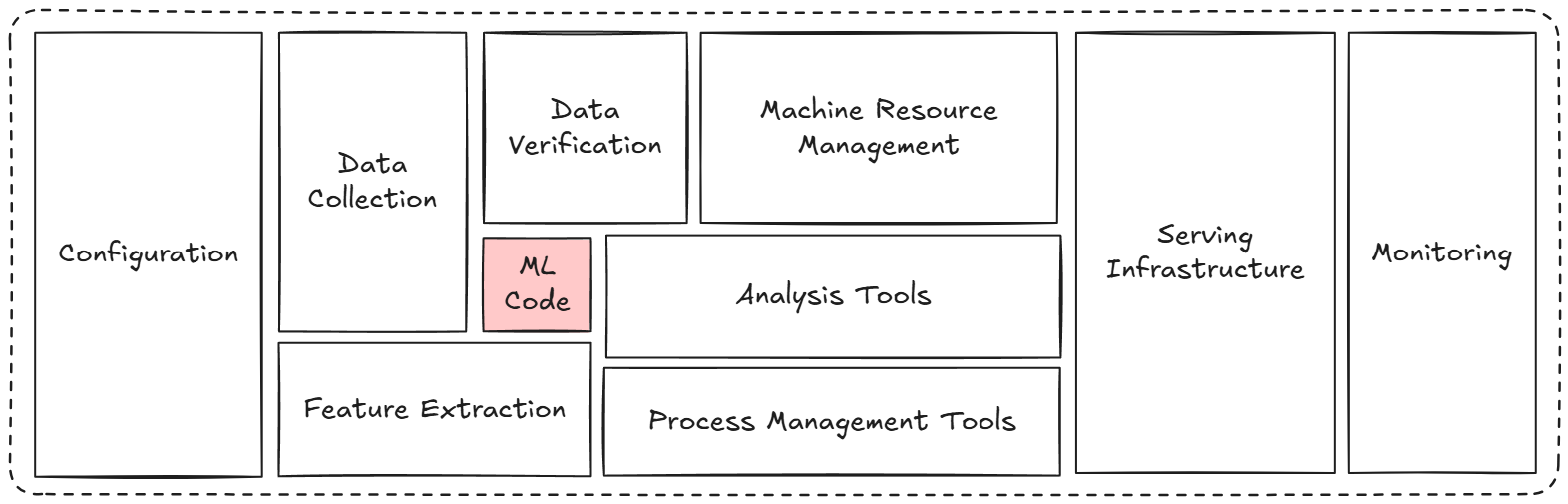
MLOps seeks to manage this complexity by applying reliable software engineering and DevOps practices to ML systems, ensuring that all these components work in concert to deliver value.
We are starting this MLOps and LLMOps crash course to provide you with a thorough explanation and systems-level thinking to build AI models for production settings.
Just as the MCP crash course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
As we progress, we will see how we can develop the critical thinking required for taking our models to the next stage and what exactly the framework should be for that.
In this crash course, we’ll begin with the fundamentals of MLOps, incorporate LLMOps, and progressively deepen our understanding with each chapter.
As for this first part, we shall focus on laying the foundation by exploring what MLOps is, why it matters, and the lifecycle of machine learning models.
Let's begin!
Why does MLOps matter?
Building a highly accurate model in a notebook is just the beginning of the journey.
Once deployed, ML models face changing real-world conditions: users may behave differently over time, data may drift, and model performance can decay.
In other words, a model’s quality or usefulness does not remain static after deployment.
The real world changes: users might behave differently over time, adversaries might try to game your model, or simply the initial model might not perform as well on new data as on the old data it was trained on.
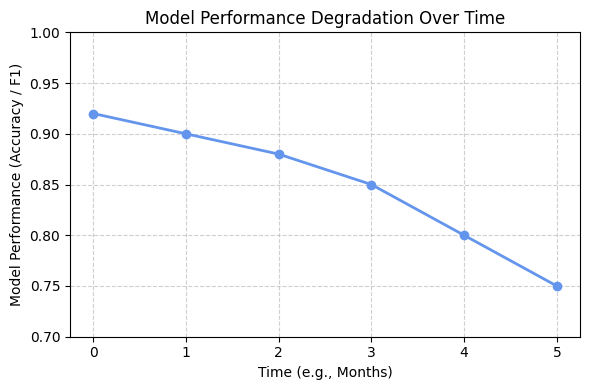
In the absence of proper operations, an accurate model can quickly become unreliable or even harmful when serving customers.
In production, an ML system must run continuously, often 24/7, and handle evolving data and usage patterns, all while meeting requirements for latency, throughput, and quality.
Inadequate MLOps can lead to stale or incorrect models lingering in production, causing bad predictions that hurt the business.
For instance, a model making flawed financial decisions or inappropriate content recommendations.
Without proper MLOps, teams often end up with manual, brittle processes for model deployment. Data scientists might manually prepare data and hand off models to engineers for one-off production integration, resulting in slow iteration and error-prone deployments.

Before the advent of mature MLOps, building and updating ML systems was slow and laborious, requiring significant resources and cross-team coordination for each new model. This led to problems like:
- Slow time to market: Weeks or months to deploy a new model, due to ad-hoc processes and lengthy hand-offs.
- Fragile pipelines: Manual steps that easily break.
- Scaling issues: Hard to handle growing data or model complexity without automation.
Effective MLOps addresses these risks by establishing processes to continuously monitor, evaluate, and improve models after deployment.
Overall, MLOps can be thought of as “DevOps for ML,” but more nuanced.
It is a set of practices, tools, and team processes that aim to build, deploy, and maintain machine learning models in production reliably and efficiently.
This includes collaboration between data scientists and engineers, automation of ML pipelines, and applying software best practices to ML, like testing, version control, continuous integration, etc.
By putting the right infrastructure and workflow in place, MLOps enables us to iterate quickly on models while keeping them running stably in a live environment.
In further sections, we’ll dive into how production ML systems differ from traditional software and the lifecycle of ML system design.
MLOps vs. DevOps and traditional software systems
Building and deploying ML systems is in many ways an extension of traditional software engineering, but there are important differences to highlight.
Development operations (also called DevOps) refers to the best practices that software teams use to shorten development cycles, maintain quality through continuous integration/deployment (CI/CD), and reliably operate services.
MLOps borrows these principles but extends them to deal with the unique challenges of ML. Let’s compare how an ML production pipeline differs from a standard software project:
Experimental development vs. deterministic development
Writing traditional software is typically a deterministic process, but in ML development, the process is highly experimental and data-driven.
You try multiple algorithms, features, and hyperparameters to find what works best.
The code itself is not necessarily buggy, but the model might simply not be accurate enough to be deployed.
Thus, there’s an added challenge of tracking experiments, handling stochastic results (due to random initialization, etc.), to ensure the reproducibility of results at later stages if needed.

The iterative nature of model training means versioning data and models (not just code) becomes critical, something that traditional DevOps doesn’t cover by default.
Testing complexity
In standard software, you write unit tests and integration tests to verify functionality.
ML systems require additional testing: not only do we need unit tests for our data preprocessing steps and any other code, but we also need to validate data quality and test the trained model’s performance.
For example, we might want to test that the model’s accuracy on a hold-out dataset meets a certain threshold, or that there is no data leakage.
There’s also the concept of training/serving skew, wherein we must ensure the data fed into the model in production is consistent with what was used in training (feature distributions, etc.). This requires careful validation and monitoring in production.
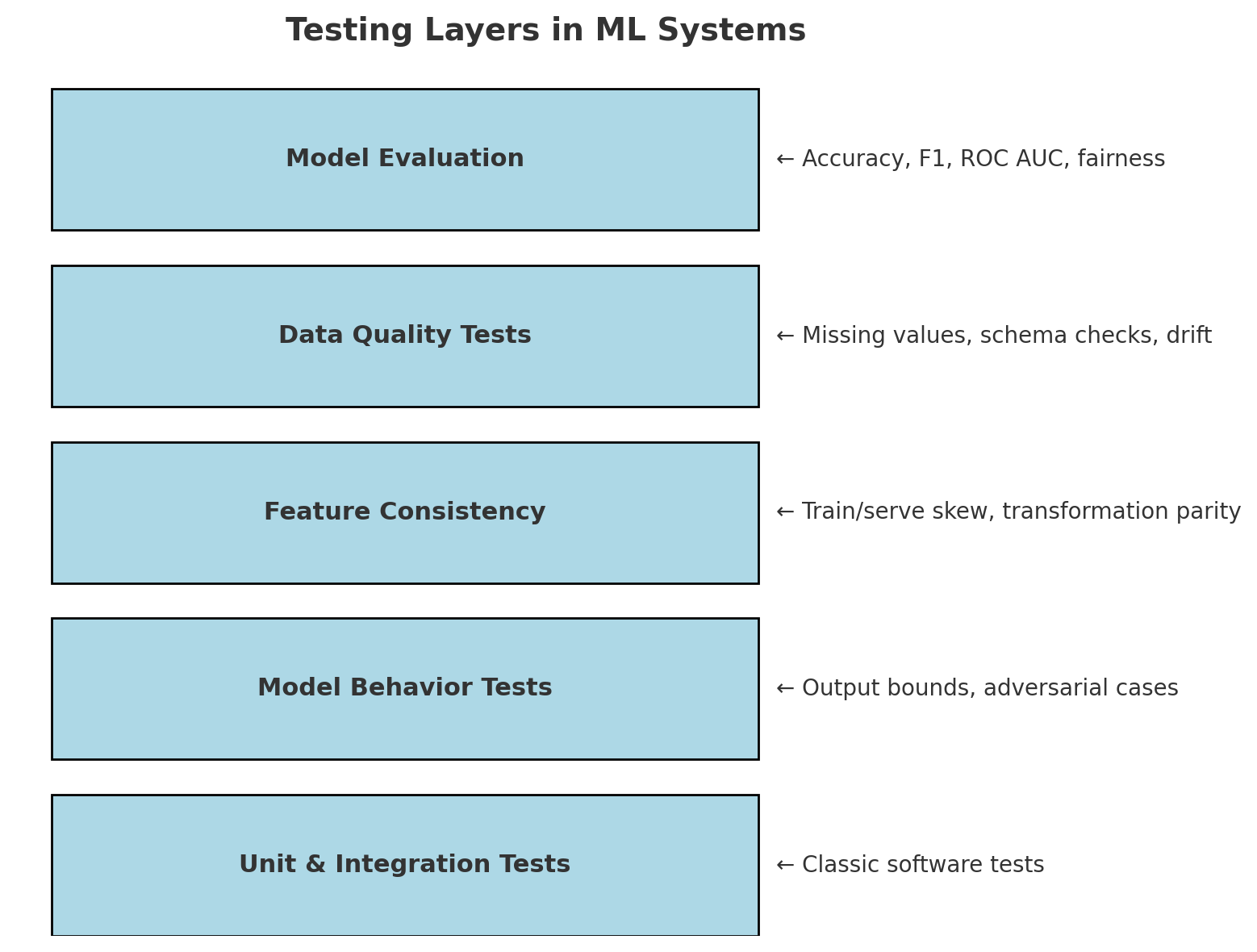
In short, an ML system’s “correctness” isn’t just about code logic, but also about statistical performance, which makes testing more involved.
Deployment and updates
In traditional software CI/CD, deploying a new version of an application is a relatively straightforward push of code through staging to production.
In ML, a “new version” of the system often means retraining a model with new data or updated parameters, which itself is a multi-step pipeline.
Deployment isn’t just shipping a binary; it may involve a whole automated pipeline that periodically retrains and deploys models. For example, retrain a model nightly with the latest data and then serve it.
Automating this pipeline is a major focus of MLOps, which introduces ideas like continuous training (CT) in addition to CI/CD.