A Practical Deep Dive Into Memory Optimization for Agentic Systems (Part A)
AI Agents Crash Course—Part 15 (with implementation).
Introduction
When you speak with AI assistants such as ChatGPT or Claude, it often appears that they remember what you said before.

In reality, they do not.
Every request to a large language model is stateless, meaning the model only knows what is contained in the prompt you send at that moment.
To simulate memory, the system has to manage context explicitly: choosing what to keep, what to discard, and what to retrieve before each new model call.
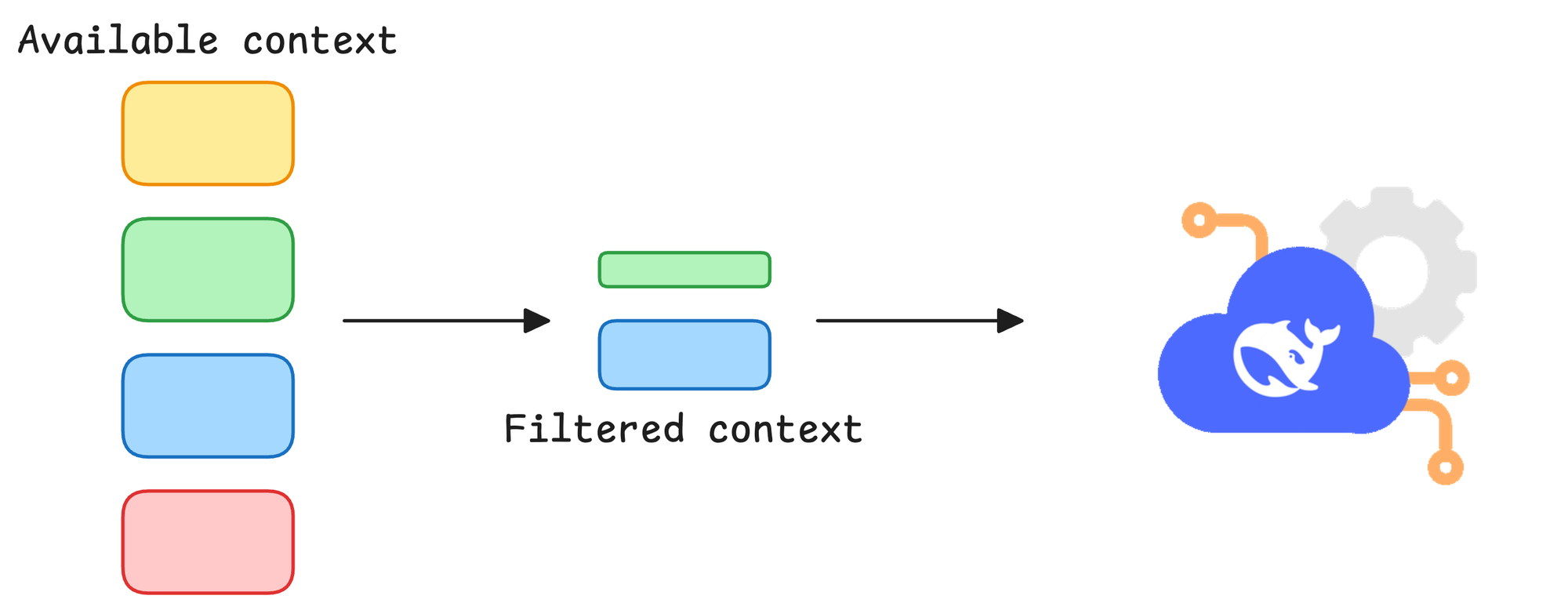
This is why memory is not a property of the model itself. It is a system design problem.
Before we go deeper, it helps to separate memory from two closely related concepts: knowledge and tools, which we have already discussed in previous parts:
- Knowledge refers to information that is static or global. This can be a knowledge base, documentation, or facts that the model learned during training. None of this changes based on user interactions. It is background information that the agent can access at any time.
- Tools fill yet another role. They let an agent fetch, calculate, or derive information on demand. A web browser, a database query, or a calculator is a tool. Tools can help the agent access information, but they do not remember anything by default. Memory fills that gap by retaining relevant details for future use.
Memory is different from both.
It is dynamic and contextual. It consists of data that an agent stores during its operations, such as conversation history, user preferences, previous outputs, or the state of an ongoing task.
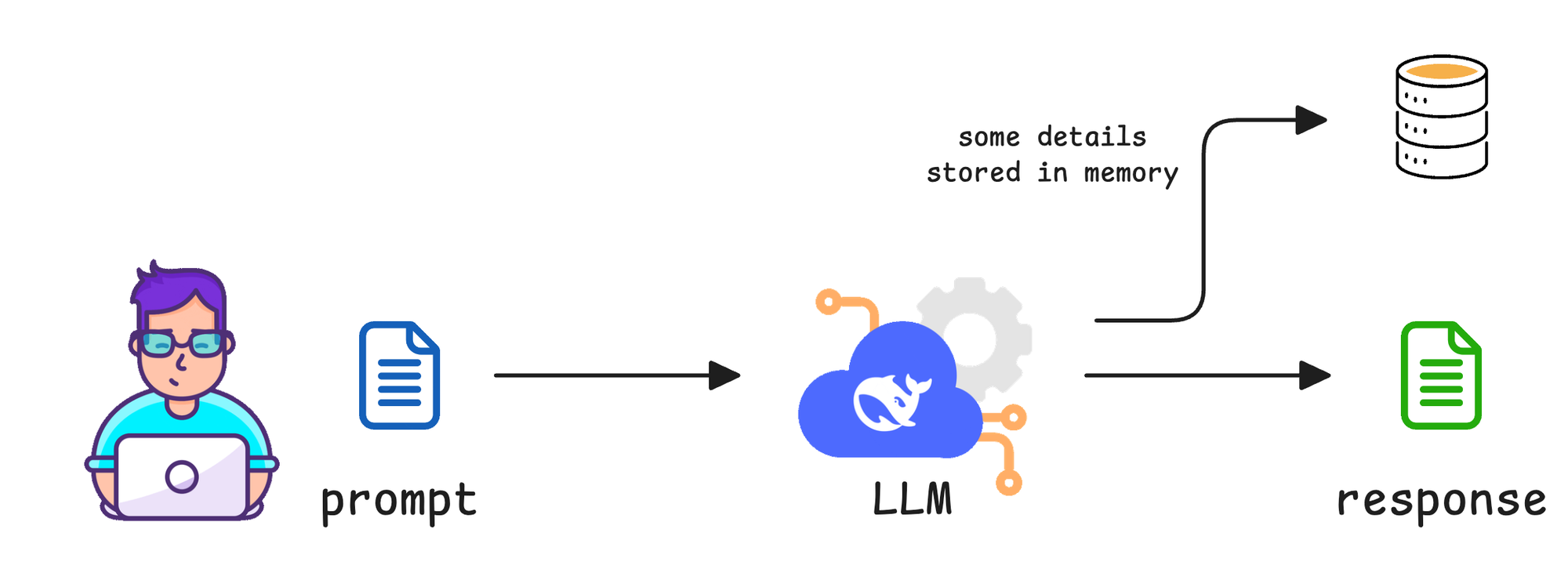
Memory tells the agent what has been happening over time, not just what is true about the world.
This distinction becomes clear when you consider a real production agent system.
If a system is running without memory, every interaction is a blank slate. It doesn’t matter if the user told the agent their name five seconds ago because it’s already forgotten.
If the agent helped troubleshoot an issue in the last session, it won’t remember any of it now.
This leads to several problems:
- Users have to repeat themselves constantly.
- Agents lose context between steps of a multi-turn task.
- Personalization becomes impossible.
- Agents can't "learn" from their past experiences, even within the same session.
With memory, however, your agent becomes context-aware.
It can remember facts like:
- “You like to eat Pizza without capsicum.”
- “This ticket is about login errors in the mobile app.”
- “We’ve already generated a draft for this topic.”
- “The user rejected the last suggestion. Don’t propose it again.”
In other words, an agent with memory can recall what you asked or told it earlier, or remember your name and preferences in a subsequent session.
These are several key benefits of integrating a robust memory system into Agents:
- Context retention: The agent can carry on a coherent dialogue or workflow, referring back to earlier parts of the conversation without providing all details again and again. This makes multi-turn interactions more natural and consistent.
- Personalization: The agent can store user-specific information (like a user’s name, past queries, or preferences) and use it to tailor future responses for that particular user.
- Continuous learning: By remembering outcomes and facts from previous runs, the agent accumulates experience. Over time, it can improve decision-making or avoid repeating mistakes by referencing what it learned earlier.
Need for memory optimization
While the above discussion highlights the importance of memory, let's understand it more from a context perspective.
Memory management is a crucial aspect when working with AI agents. An AI agent's ability to retain and utilize information from previous interactions is essential for generating coherent and contextually appropriate responses.
The context problem in production
Many developers assume that the ever-increasing context windows (e.g., models supporting 100K, 200K, or even 1 million tokens) will eliminate the need for memory management.
They think that with a large enough window, you can simply throw everything into a prompt you might need, be it tools, documents, instructions, and let the model take care of the rest.
Unfortunately, this assumption breaks down the moment you move from a playground script to a production-grade system.
- Every token you send to the LLM costs money. Sending a massive, unmanaged 200,000-token conversation history on every single turn is financially unsustainable. Cutting down these unnecessary token costs is how you move towards effective memory management.
- Injecting enormous contexts into every prompt leads to high inference latency. If your user is waiting 10 or 15 seconds for a response, your system is failing in production. Agents must be fast.
- Simply including everything in the prompt doesn't mean the agent will use it. This is the most subtle, and arguably most important, failure mode.
- Pioneering research, famously known as the "Needle in a Haystack" findings, proved that information buried deep in a massive context is often ignored or retrieved unreliably. The context window is wide, but the focus is narrow.
- Further research in Context Engineering shows that LLMs often suffer from recency decay. If a crucial, recently added instruction is surrounded by long-standing (but less important) system instructions or verbose chat history, the model might just forget the new rule.
This was discovered by the Google DeepMind team in the Gemini 2.5 technical report. Here is the snippet from the paper.

Instead of using its training to develop new strategies, the agent became fixated on repeating past actions from its extensive context history.
This teaches us that memory is not a passive storage mechanism rather it's an active process of strategic placement. We have to carefully engineer the context to ensure the agent uses the right information at the right time.
These points clearly show that it’s not just about what the LLM remembers, but how you present it to the LLM is also a crucial aspect of building effective agents for production.
An agent must actively manage its memory to ensure the most relevant facts are prioritized, which necessitates a system more nuanced than a simple history dump.
However, developers may encounter challenges maintaining consistent memory over prolonged interactions or tasks.
Just as humans selectively remember important details and let trivial ones fade, AI agents need clever strategies to remember what matters and forget what doesn’t.
We hope this clarifies the importance of memory in Agents.
Next, let's move to practical implementations.
LangGraph ecosystem
In earlier parts of the Agents' crash course, we primarily used CrewAI. But in this one, we are going to utilize LangGraph.
LangGraph is designed to help developers create stateful, multi-actor applications that leverage the capabilities of LLMs. Unlike traditional linear workflows, LangGraph introduces a graph-based execution model where an AI-driven workflow is represented as a graph of nodes and edges with the additional persistent state management and multi-agent coordination, making it better suited for advanced applications.
This structure allows for more dynamic and flexible interactions, enabling the development of sophisticated multi-agent setups.
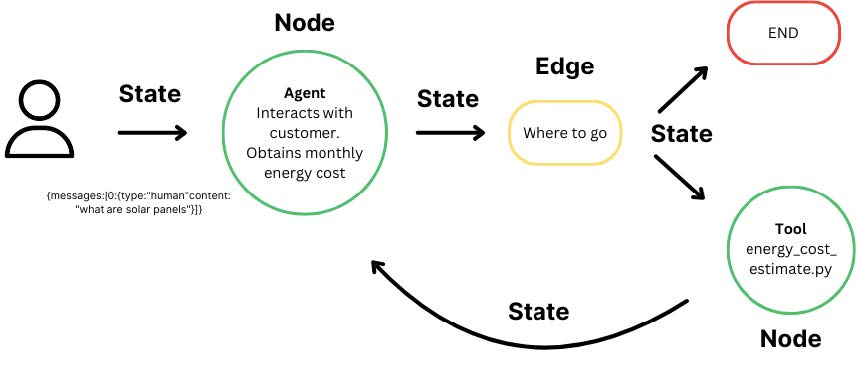
Before building your own agentic applications, it’s crucial to grasp the foundational building blocks of LangGraph. These components, State, Nodes, and Edges, each play unique roles, enabling you to orchestrate complex AI workflows seamlessly.
Before we start layering memory systems, we need to understand the basic building blocks that LangGraph provides. These concepts are small and simple on their own, but together they form the execution model that every agent runs on.
The goal here is not to teach you every LangGraph feature. It’s to give you just enough of the mental model so that when we begin adding memory, you know exactly where it fits and why certain patterns work the way they do.
Firstly, LangGraph is built around a few core ideas:
- state - the data that flows through your graph.
- nodes - small functions that read and update the state.
- edges - how control moves from one node to another.
In this section, we will use a simple example to demonstrate how LangGraph updates a number in the state. After understanding this, it will be much easier to reason about how it updates messages, summaries, and long-term memory later.
Setup
Before moving on to the code, let's first complete our setup and install the required dependencies.
We will use OpenRouter as our main LLM provider for this tutorial. It provides a single API to connect to all the LLM providers out there.
Go to OpenRouter, create an account and get your API key, and store it in a .env file:
Next, we load this key into our environment as follows:
OpenRouter is compatible with the OpenAI chat completions API, so we can use ChatOpenAI with a custom base_url to define our LLM.
model is the model identifier from OpenRouter. You can swap this out for Claude, Gemini, or any other open source model if you like.
Now we are all set to get on with understanding the LangGraph concepts.
State
Every LangGraph workflow revolves around a single shared state object, which is like an Agent's workspace that it keeps adding to, reading from, and modifying as it thinks, invokes tools, and responds to the user.
It holds everything the Agent knows at any point in time.
For instance, below, we define a state that only tracks a single integer called count:
In the code above: